一、一个典型的中型制造企业数据困局
去年秋天,我们团队走访了浙江一家年营收约8亿元的中型精密零部件制造企业。这家企业有三条主力产品线,客户覆盖汽车零部件和工业设备两个领域,员工近800人。走访前,对方IT负责人给我们的邮件里写了这样一句话:“我们的数据已经多到快要把自己淹死了。”
到现场一看,这句话一点不夸张。
过去八年,这家企业陆续上线了ERP、MES、WMS、PLM、CRM、OA六个核心业务系统,加上车间层的SCADA系统和外部采购的行业数据接口,总共运行着11个数据源。每个系统单独拎出来都跑得不错,但数据之间几乎不是通的,或者说,是硬通的。
生产部每天早上需要从MES导出Excel,手工整理后发给品质部做良率分析。计划部从ERP拿到订单数据后,要等仓库手工汇总WMS库存才能排产。财务部在做成本核算时,每次都要发邮件让人手工补录遗漏的物料消耗数据。整体算下来,跨系统的数据流转平均延迟超过24小时,且口径经常不一致,同一个产量指标,MES算一套、ERP算一套、财务再算一套。
这不是个别现象。据IDC数据,中型制造企业平均使用8-12个独立业务系统,其中超过60%的企业存在三个以上的关键数据断裂点,也就是说,日常经营决策依赖的数据链路中至少有3个环节靠手工或半手工方式衔接。
二、选型前的自我诊断:不是工具问题,是方法问题
这家企业的IT团队并不弱。三名开发工程师、两名运维人员,都有五年以上经验。问题出在思路。
第一轮他们尝试过自己写Python脚本做数据同步,结果写得越快,维护越痛苦。脚本没有统一的调度和监控,一个接口变更就要改七八个地方。第二轮采购了一个开源ETL工具(Kettle),但团队很快发现,开源工具在能跑起来和能长期稳定运行之间存在巨大差距:没有任务监控告警、没有数据血缘追溯、没有版本管理,一旦出了问题,排查起来比写脚本还花时间。
第三次,他们决定认真做一次正式的选型。核心团队花了两周时间,把问题梳理成三个层面:
第一层:数据接入问题:11个数据源覆盖关系型数据库(MySQL、Oracle)、文件数据、API接口、SCADA时序数据,需要一个工具能统一接入,而不是每个数据源单独写一套对接逻辑。
第二层:数据治理问题:口径不统一、数据质量参差不齐、缺少标准化的指标体系。需要一个工具能承载数据标准、能追踪数据从哪来到哪去(血缘),而不是只做管道。
第三层:持续运营问题:选型不是为了解决今天的11个系统,而是为了未来三到五年,系统数量可能翻倍、数据量持续增长。工具需要有企业级的任务调度、权限管控、资源迁移能力,不能是一个做完就丢的项目型工具。
这个三层诊断框架,后来被他们的IT总监总结成一句话:“我们需要的不是一把更快的铲子,而是一套能持续运转的管线系统。”
三、选型过程:四轮筛选后的取舍
基于三层诊断,团队设定了一套选型标准,按四轮筛选推进:
第一轮:数据源覆盖筛。 是否能原生接入MySQL、Oracle、SCADA时序数据、RestAPI、文件数据?是否能读写简道云(公司部分部门在用简道云做轻应用)?本轮淘汰了所有只支持关系型数据库的工具。
第二轮:治理能力筛。 是否有数据血缘追踪?是否有完整的API生命周期管理?是否支持三级权限体系?本轮淘汰了大部分只做数据搬运的工具。
第三轮:稳定性验证。 实际部署测试环境,用真实数据跑一个月。关注指标:CDC实时同步断连后能否自动恢复、批量同步的吞吐量、任务失败的告警和重试机制。
第四轮:扩展性评估。 是否与团队已有的BI工具(FineBI)天然协同?是否支持国产数据库(公司计划两年内部分迁移到达梦)?是否支持Python/Spark扩展计算?
最终进入终评的是三款产品。其中,FineDataLink在三轮关键决策点的表现决定了最终选择:
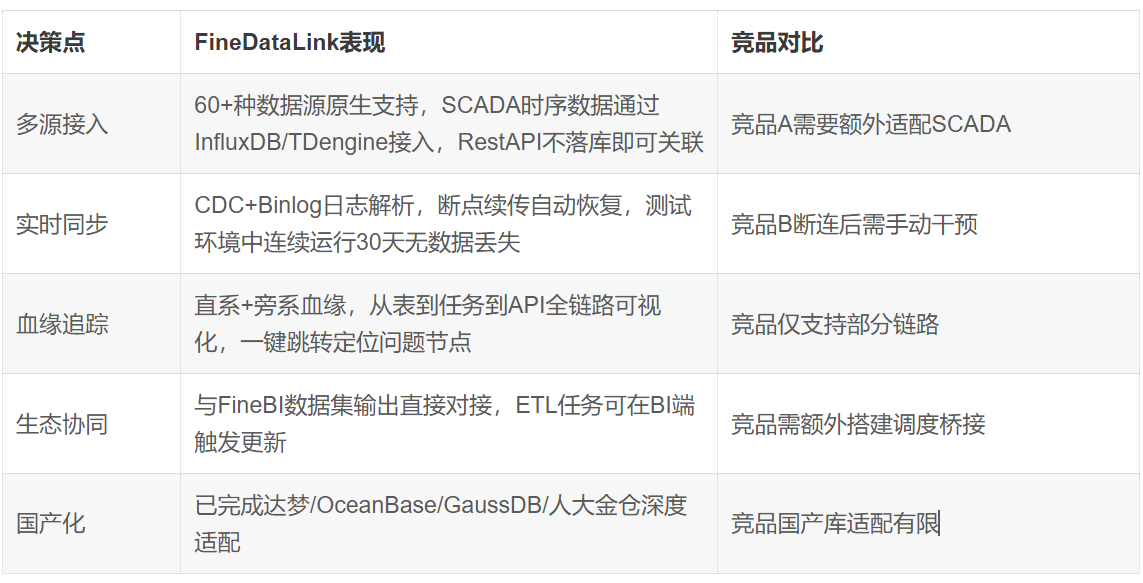
四、落地过程:分三步,不走弯路
选型确定后,实际落地分三个阶段:
第一阶段(2周):数据接入与标准化。 不是一口气接完11个数据源,而是按业务优先级先接MES、ERP、WMS三个核心系统。同步建立数据标准字典,统一关键指标口径(产量、不良率、设备稼动率等17个核心指标)。这一步看似慢,实际上避免了后续数据乱上加乱。
第二阶段(4周):构建数据仓库分层体系。 参照行业最佳实践,建立ODS→DW→DM三层数据架构。利用FineDataLink的数据转换算子(字段映射、JSON解析、分组汇总、数据关联等),将分散在各系统中的原始数据逐层清洗、整合、标准化。关键动作是建立了拉链表,历史数据变化可追溯,管理层能按任意时间点回溯经营状态。
第三阶段(2周):API服务化与应用对接。 用FineDataLink数据服务模块,将标准化后的数据以Restful API形式发布,对接FineBI分析看板、OA审批流和车间大屏。5分钟完成一个API发布,接口自带鉴权和频率控制,不需要额外开发安全层。
整个落地过程实际耗时8周,比原计划(12周)提前了三分之一。团队反馈,最大的提速点不是工具本身有多快,而是调试和排错的时间大幅减少。血缘原因快速定位问题、版本管理让试错成本可控、消息通知让异常第一时间暴露。
五、落地后的变化:一些看得见的数字
上线运行三个月后,几个关键指标变化显著:
● 数据流转延迟:从平均超过24小时缩短到10秒以内(实时管道同步)。车间生产数据延迟从4小时降到30秒。
● 数据准确率:关键指标的跨系统一致性从不足70%提升到100%。之前生产、财务、计划三部门各算各的问题彻底消除。
● 报表准备效率:月度经营分析会的数据准备时间从5个工作日降为实时拉取。管理层在会议上可以直接钻取到问题产线,而不是等会后三天出分析报告。
● IT团队产能释放:每月节省约120小时的数据搬运和排错工时,释放出来的产能转向了数据分析应用开发和业务部门数据赋能。
但真正让我们印象深刻的是IT总监的一句话:“以前系统出数据问题,我们是最后一个知道的,通常是业务部门来投诉。现在是第一个知道的,消息通知第一时间推送到企业微信,问题还没影响业务就已经在修了。”这种从被动救火到主动运维的转变,才是数据治理真正落地的标志。
六、复盘:中型制造企业数据治理的三个关键认知
回看这个案例,有三条认知值得提炼:
第一,数据治理不是先乱后治,而是边治边用。 很多企业有一个误区:先把所有数据接进来,建一个大而全的数据仓库,再慢慢治理。实践一再证明这条路走不通。正确的方式是用到什么数据就先治理什么,按业务优先级逐步推进,每治理一部分就产生一部分业务价值。这家企业从三个核心系统入手,两个月内就看到了经营分析效率的提升,这给了团队继续推进的信心和资源。
第二,工具选型的核心不是功能多,而是治理能力内建。 单纯看支持多少种数据源、能跑多快,其实门槛不高。真正的分水岭在于:这个工具是否把数据治理能力(血缘、权限、版本、监控)内建在产品逻辑里。如果这些能力要靠外部补丁或人工流程来实现,随着数据规模增长,技术债务会指数级上升。
第三,生态价值比单点能力更具长期意义。 选择FineDataLink的一个关键考量,是它与FineBI、FineReport、简道云的天然融合。当企业未来需要扩展数据分析、报表展示或业务应用搭建时,不需要再为对接付出额外的集成成本。在一个厂商生态内解决数据全链路问题,长期来看运维复杂度和隐性成本都更低。
七、结语
数据治理在中小制造企业里,常常被当作大厂才需要的东西。但现实是,越是中型企业,数据混乱对经营效率的拖累越严重。大厂有专业数据团队扛着,中型企业数据出问题往往直接传导到业务决策。
这家企业的经历证明了一件事:中型制造企业完全可以在不增加IT编制、不推翻现有系统的情况下,通过合理的工具选型和分步推进,把数据从混乱变成驱动。 关键在于,不要试图用更快的搬运来解决问题,而是用治理能力内建的工具来建立可持续的数据供给体系。
从混乱到数据驱动,差的不是更好的脚本,而是一次对数据治理方法的重新理解。