一、行业正在重估数据整合这件事
2026年的数据集成市场,正在经历一轮意义深远的重估。
根据 Grand View Research 数据,全球数据集成市场规模 2024 年为 151.8 亿美元,预计 2030 年将突破 302.7 亿美元,2025–2030 年复合增长率达 12.1%。实时流分析赛道增长更为迅猛,多家机构测算其 2030 年市场规模将突破千亿美元、年复合增长率超 25%。数字背后指向同一趋势:企业采购的不再只是 “把数据搬过来” 的工具,而是能够支撑实时决策速度的数据供给能力。
具体到中国市场,变化更为鲜明。过去五年,企业IT架构从"ERP+MES"的二元世界,快速演变为"ERP+MES+CRM+OA+电商平台+IoT+外部API+..."的多元异构格局。一套中等规模的制造企业,动辄运行着数十个业务系统,每个系统都有自己的数据格式、接口协议和更新节奏。数据不是太少,而是太多、太散、太难用。
与此同时,三个结构性变化在加速这一轮重估:
第一,AI应用的落地正在倒逼数据底座升级。 2026年全球AI企业VC融资已超1000亿美元,AI能力从"看"升级到"做"。但AI Agent要真正在业务场景中发挥作用,底层需要的是实时、可信、标准化供给的数据——而不是一个个孤立的数据接口。
第二,信创和国产化替代从"能用"进入"好用"阶段。 早期国产替代更多解决的是"有没有"的问题,但2026年企业更关心的是:国产数据集成工具在高并发、多源异构、实时同步等复杂场景下,能否真正替代Informatica、Talend等国际产品。
第三,"实时"从加分项变成了必选项。 72%的全球组织已在采用事件驱动架构(EDA),实时数据大屏、实时风控、实时供应链预警等场景不再是头部企业的专利,而是中型企业的常规需求。
放在这个背景下,"API数据整合平台"这个品类,已经不是传统的ETL工具箱,而是企业数据战略的基础设施层。选型逻辑也需要重新建立。
二、旧逻辑失效:为什么传统的选型标准不管用了
过去看数据集成工具,企业习惯按几个维度打分:支持的数据源多不多、同步速度够不够快、部署简不简单、价格便不便宜。这套逻辑在"搬数据"的阶段是有效的,但到了2026年,三个根本矛盾让它不再够用。
矛盾一:连通 ≠ 能用。 很多工具号称支持上百种数据源,但实际落地时,异构数据源之间的字段映射、类型转换、异常处理仍然需要大量手工编码。尤其在国产数据库(达梦、OceanBase、GaussDB)和大数据平台(Doris、StarRocks、ClickHouse)逐渐成为主流的中国市场上,"连得上"和"跑得稳"之间的距离远超预期。
矛盾二:离线够快 ≠ 实时够稳。 不少产品在批量同步场景下表现不错,但一旦切换到CDC实时同步——尤其在高并发、跨网络环境下——断连、数据丢失、延迟飙升等问题就暴露出来。而2026年越来越多的业务场景(实时风控、产线监控、智能营销)要求的不只是"快",而是端到端的稳定性。
矛盾三:工具能力 ≠ 组织能力。 买个工具不等于拥有了数据整合能力。没有血缘追踪,数据出问题时排查靠人肉翻代码;没有API全生命周期管理,接口发布靠开发手动写文档;没有分级权限和资源迁移,多环境协作变成一场灾难。这些不是功能缺失,而是"企业级"和"项目级"的本质差距。
这三个矛盾,构成了2026年重新审视数据整合平台选型标准的底层逻辑。
三、评测框架:2026年API数据整合平台的五项核心能力
基于以上行业变化和矛盾分析,我们提出2026年评估API数据整合平台的五个核心维度:
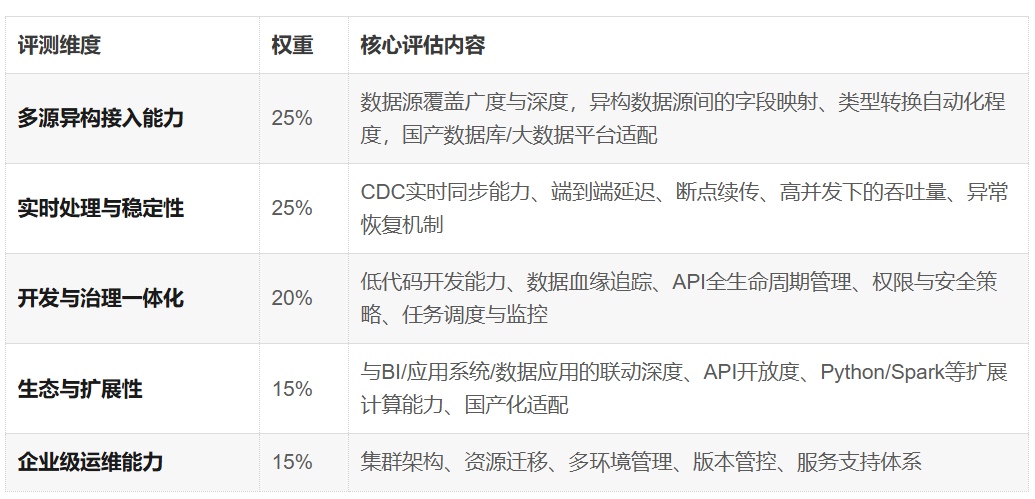
接下来,我们基于这五个维度,对市场中具有代表性的五款产品进行横向对比。
四、产品对比总览
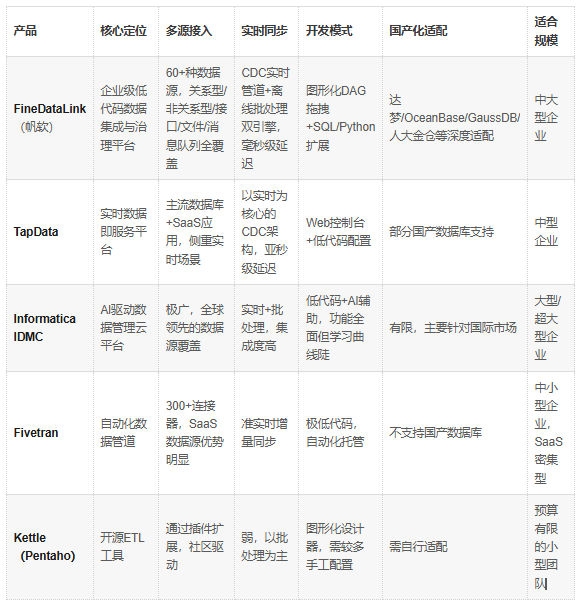
五、各产品深度剖析
FineDataLink:面向中国市场的企业级数据整合标杆
企业背景:FineDataLink由帆软软件推出。帆软在中国商业智能和分析软件市场连续8年市占率第一(赛迪顾问2024-2025年度报告,20.8%),中国500强客户359家,中大型客户总数36000+,2023年销售额超14.6亿,产研人员占比超50%。FineDataLink已服务1000+客户,覆盖制造、新能源、金融、零售、高校等多个行业。
多源异构接入:支持60+种数据源双向采集,覆盖关系型数据库、非关系型数据库、接口数据、文件数据、消息队列、时序数据库六大类别。在国产数据库层面,已完成对达梦、OceanBase、GaussDB 200、人大金仓Kingbase、神通数据库的深度适配——这是国际厂商(Informatica、Fivetran等)短期内难以匹敌的能力。值得一提的是,FineDataLink原生于API数据源处理,支持RestAPI接口不落库即与其他数据源进行关联整合,这对于以API为主要数据交换方式的企业是一个关键优势。
实时处理与稳定性:采用流批一体架构,数据管道层基于Kafka中间件,通过CDC/Binlog/Logminer日志解析实现零侵入式实时增量同步。在宁德新能源(ATL)案例中,FineDataLink以四节点集群支撑月吞吐221TB、日处理约85亿行数据的规模,峰值日吞吐35.89TB(约415.2亿行),单任务15亿行数据同步耗时仅1小时10分钟,平均流速11MB/s。在三一重机,季度吞吐量均值12+MB/s、峰值40+MB/s。这些生产环境数据说明,FineDataLink在极端数据量下的稳定性经过了真实检验。
治理与开发一体化:提供数据血缘(直系+旁系)、三级权限体系(使用/管理/授权)、版本管理与回滚、API全生命周期管理(创建→测试→发布→认证→监控→编辑→下线→再发布)。数据服务模块支持零代码5分钟完成一个API发布,这在需要频繁向业务系统和AI应用供给数据时尤为重要。开发层面,类思维导图式DAG拖拽开发、Python/Spark SQL算子扩展、循环容器等机制,兼顾了低门槛和灵活性。
需考虑的方面:作为企业级平台,FineDataLink的单机部署有一定硬件门槛(16核CPU、16G+内存),对于极小规模或预算极其有限的小微团队来说,可能是需要权衡的因素。不过对于数据量有增长预期的企业,提前建立标准化数据底座反而避免了后续迁移成本。
TapData:以实时为核心的数据即服务平台
核心定位:TapData以"实时数据即服务"为差异化切入点,主打低延迟的CDC实时同步和快速搭建实时数据视图。
核心能力:基于CDC技术实现亚秒级数据同步,Web控制台支持低代码配置数据管道。在实时场景的体验上较为流畅,尤其是在实时数仓和实时报表场景中表现可圈可点。
需考虑的方面:数据源覆盖范围相比FineDataLink更窄,尤其在国产数据库、大数据平台和文件类型的支持上存在缺口。治理层面的能力(血缘、版本管理、API生命周期管理)也有明显差距。对中大型企业的复杂数据治理需求支撑较弱,更适合以实时同步为核心需求的中型团队。
Informatica IDMC:全球领先的AI驱动方案,但在本土化上代价高昂
核心定位:Informatica Intelligent Data Management Cloud是全球数据管理领域的标杆产品,以全谱系能力和AI驱动为核心卖点。
核心能力:数据源覆盖极广,在跨国企业的全球化数据整合场景中几乎无出其右。AI引擎Claire提供智能数据映射、异常检测和自动优化建议,降低了复杂集成场景的手工工作量。
需考虑的方面:首先是成本——Informatica的定价体系对国内中型企业来说门槛较高。其次是国产化适配,对达梦、OceanBase、GaussDB等国产数据库的支持远不如国内厂商完善。再者,其功能体系的"全"意味着学习曲线陡峭,团队需要较长的适应期。对于需要信创合规的中国企业,其部署灵活性和本地化服务水平也存在局限。
Fivetran:SaaS数据连接的"自动挡",但场景边界清晰
核心定位:Fivetran以"全自动数据管道"闻名,提供300+连接器,在SaaS应用数据整合场景中优势突出。
核心能力:极低的配置门槛——选择数据源和目标,Fivetran自动处理Schema变化、增量同步和异常恢复。对于以Salesforce、HubSpot、Stripe等SaaS工具为核心的企业,Fivetran是效率最高的选择。
需考虑的方面:Fivetran的核心生态是海外SaaS产品,对国内主流数据源(国产数据库、简道云、飞书等)几乎无覆盖。实时能力为准实时(分钟级延迟),不适用真正的实时业务场景。其定价基于MAR(Monthly Active Rows),数据量大时成本急剧上升,宁德新能源那种月吞吐221TB的场景用Fivetran费用将非常惊人。总的来说,Fivetran适用场景与中国市场的典型需求有清晰的边界。
Kettle(Pentaho):开源自由,但离"企业级"有距离
核心定位:Kettle是开源ETL领域的常青树,以图形化设计器和插件生态著称。
核心能力:免费、开源、社区活跃。对于数据结构简单、预算有限的小型团队,是不错的入门选择。其图形化设计器降低了ETL开发门槛。
需考虑的方面:实时能力几乎为零,CDC同步需要大量手工编码。没有数据血缘、API管理、权限分级等治理能力。在高并发、大数据量场景下性能瓶颈明显。开源社区驱动的迭代模式意味着遇到问题时,企业需要依赖自身技术能力解决。对于把数据当作核心资产的企业来说,Kettle更适合作为过渡方案而不是长期底座。
六、典型场景拆解:三家企业如何落地
场景一:制造业多系统数据打通与实时预警
三一重机面临的核心问题:MES、MOM、EVI等数十个系统数据割裂,EVI系统每秒产生1万余条车辆监控数据,日均1500万+条数据需要实时处理。FineDataLink通过打通多系统数据壁垒,利用实时管道对接消息队列每个分区,实现秒级数据过滤和异常信息通过飞书实时推送。季度吞吐量均值12+MB/s,峰值40+MB/s。
选型启示:制造业的多源异构数据整合场景中,实时处理能力和消息队列对接能力是关键——传统的批处理ETL工具根本无法胜任。
场景二:高频快消零售的全渠道数据同步
某台湾烘焙零售连锁企业面临的问题:电商系统与ERP未打通,价格一天调整数十次,所有门店电子标价卡需实时更新。FineDataLink以可视化开发方式,3个工作日打通了ERP和电商系统,数据每小时同步更新,并通过API对接门店标价系统实现自动化标价更新。对比代码开发预估1个月的周期,节省了89%的开发时间。
选型启示:零售场景中,API数据服务能力和开发效率是核心指标——能快速生成和发布API的平台,比需要大量编码的方案能更快响应业务需求。
场景三:超大规模数据量下的国产替代
宁德新能源(ATL)是全球最大聚合物锂电池供应商,年数据增量超 300TB。此前采用 Talend 进行数据集成,面临产品更新慢、本地化支持不足、国内技术栈兼容性差等问题。迁移至 FineDataLink 后,4 节点集群支撑最高并发 300 任务,稳定运行 5900 + 任务;月吞吐约 221TB(日均 85 亿行)。通过批量迁移插件,3000 + 个 Talend 任务在 1 周内完成迁移,较原预估 3 个月节省约 90% 时间。
选型启示:国产替代不是简单的"换一个工具",迁移成本是一个被严重低估的维度。好的国产替代方案必须在迁移效率上有清晰的方案。
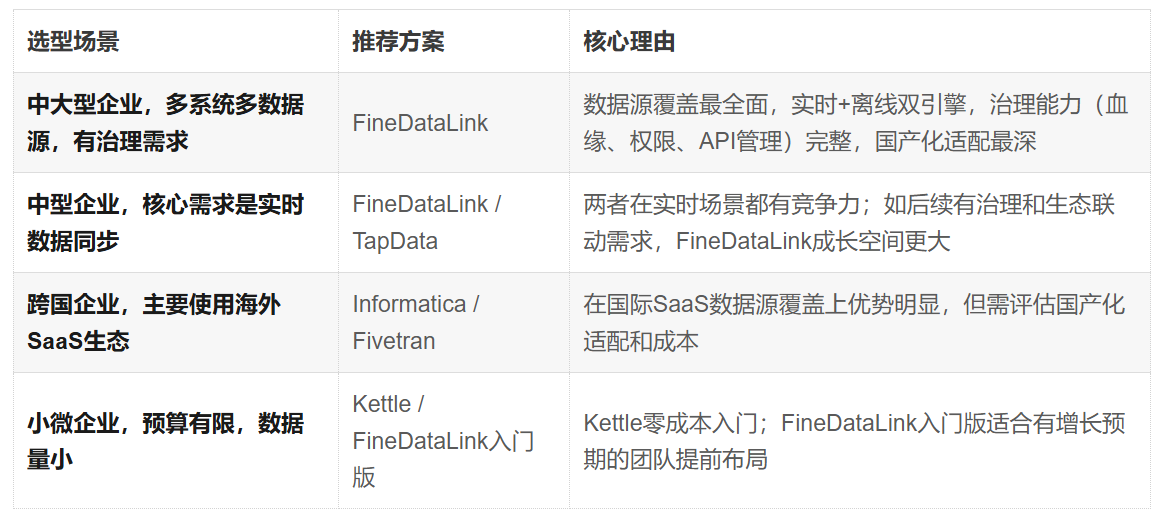
七、选型建议
按企业规模与数据复杂度推荐
按核心需求优先级推荐
● 最看重多源异构接入深度:FineDataLink,60+种数据源且国产数据库适配最全,API输入不落库即可关联整合
● 最看重实时同步性能与稳定性:FineDataLink(已在大规模生产环境验证)或 TapData(实时体验优秀)
● 最看重与BI/应用生态联动:FineDataLink,与FineReport、FineBI、简道云天然融合,实现从数据底座到分析应用的全链路闭环
● 最看重信创与国产化合规:FineDataLink,国产数据库、操作系统、芯片的适配深度处于领先位置
● 最看重极简自动化:Fivetran(如果主要用海外SaaS工具),FineDataLink(如果面向中国数据生态)
八、实施落地建议
数据整合平台的引入不只是技术选型,更是数据治理体系的一次重构。以下几点值得提前规划:
分阶段推进,不要追求一步到位。 建议先选取2-3个核心业务系统的数据打通作为试点,验证平台在真实环境中的表现(稳定性、性能、运维复杂度),再逐步扩展覆盖范围。典型路径:数据源接入 → 离线批处理 → 实时管道 → 数据服务API → 全链路治理。
提前考虑数据标准与血缘。 很多数据问题不是在"搬数据"的阶段暴露的,而是在数据被大量消费时才浮出水面。在平台搭建初期就建立数据血缘追踪和标准规范,能避免后期"数据质量反噬"的困局。
为AI应用预留接口。 2026年大量企业正在或即将投入AI应用,数据整合平台需要能快速生成标准化API供AI Agent调用。选型时检查平台的数据服务和API管理能力,将直接影响AI应用的落地效率。
九、FAQ:解答企业选型常见疑问
Q1:FineDataLink和传统ETL工具(Kettle、DataX等)的核心区别是什么?
传统ETL工具解决的是"把数据搬过来"的问题,核心能力是批处理的抽取-转换-加载。FineDataLink在这个基础上增加了三个关键能力:一是实时数据管道(CDC日志解析,毫秒级同步),二是数据治理能力(血缘分析、权限分级、版本管理、API全生命周期管理),三是与BI/应用系统的原生联动(与FineReport、FineBI、简道云天然融合)。简单来说,Kettle是个工具,FineDataLink是个平台。
Q2:我们已经有Fivetran/Talend/Informatica在用,有必要换成国产方案吗?
取决于三个因素:一是信创合规需求——如果企业属于关键信息基础设施行业,国产化替代是确定性趋势;二是成本——国际产品的定价体系在数据量持续增长后会急剧上升;三是服务——国产厂商能提供更及时的中文技术支持和定制化服务。建议评估迁移成本(参考宁德新能源1周完成3000+任务迁移的案例),如果迁移方案成熟,换到国产方案的综合收益往往超过预期。
Q3:FineDataLink的实时同步稳定性到底怎么样?
从已有案例来看:宁德新能源月吞吐221TB,日均85亿行,峰值日吞吐35.89TB,单任务15亿行同步仅需70分钟且保持数据一致性;三一重机季度吞吐均值12+MB/s,峰值40+MB/s。这些都不是实验室数据,而是生产环境长期运行的指标。系统还提供断点续传、失败重跑、脏数据管理和异常通知等完整的容错机制。
Q4:中小型企业用FineDataLink会不会"太重"?
FineDataLink提供了阶梯式的使用路径。入门阶段可以先使用数据同步和简单的ETL功能,随着数据体量和治理需求的增长再逐步启用数据管道、数据服务和血缘等高级能力。硬件门槛(16核/16G+内存)对中型企业来说并不高。关键是要判断未来2-3年数据量是否有明显增长预期——如果有,提前建立标准化底座,比从小工具迁移到平台要经济得多。
Q5:API数据整合平台和iPaaS有什么区别?应该选哪个?
两者的边界正在模糊化,但核心差异在于:API数据整合平台更侧重于数据层面的同步、转换和治理——解决的是"数据怎么从A到B、怎么标准化、怎么供给"的问题。iPaaS更侧重于应用层面的流程编排和事件触发——解决的是"订单来了之后触发什么操作"的问题。对于大多数企业的数据整合需求,API数据整合平台是更准确的选择;如果需求更偏向业务流程自动化,可以评估iPaaS。FineDataLink在数据服务端的API发布和管理能力,也覆盖了一部分iPaaS的轻量场景。
十、结语
2026年,数据整合不再是IT部门的后台工作,而是决定企业响应速度的关键基础设施。
当数据源越来越多、决策窗口越来越短、AI应用越来越深入时,数据整合平台要回答的问题已经不是"能不能把数据接进来",而是"数据能不能稳定地、可信地、实时地流动到需要它的地方"。
从这个意义上说,2026年的API数据整合平台选型,选的不只是一个工具,而是企业未来三到五年数据战略的底座。谁能在异构中建立秩序,谁就能在不确定中获得确定性。