随着“数据要素×”行动计划全面落地与工业AI深度融合,数据治理已成为制造业数字化转型的“前置战役”。但市面上的数据治理平台纷繁复杂——传统ETL工具、数据中台厂商、云原生数据集成服务、综合BI厂商的产品线,各有侧重、定位迥异。制造企业到底该如何选择一套真正“接地气”的数据治理工具?
本文从制造企业真实痛点出发,结合IDC、Gartner等权威机构评估框架,梳理六大核心选型维度,并对5款主流数据治理产品进行横向对比,为您的选型决策提供参考。
一、制造企业数据治理的“刚性需求”:三种典型场景决定选型方向
全国人大代表马新强在调研中发现,工业企业在智能化转型中普遍面临 “数据孤岛”、标准缺失、质量参差、安全风险凸显以及复合型人才匮乏等堵点难点。江苏省工信厅发布的制造业数据治理参考指引也指出,制造业普遍存在数据“孤岛”与“失真”、数据治理与标准化缺失、数据与应用场景脱节等痛点,严重制约了高质量数据集的供给。据IDC预测,2026年中国数据治理平台市场规模将突破860亿元,制造业与金融、政务三大行业合计占比超65%,制造企业正成为数据治理工具采购的主力军。
对于制造企业而言,数据治理的核心需求通常来自以下三种典型场景:
1. 多源异构数据汇聚场景:ERP、MES、WMS、CRM等系统独立运行,数据标准和格式各异,生产现场设备数据无法与业务系统打通;
2. 实时数据驱动精益管理场景:生产异常、设备报警、质量波动等现场信息需要实时触达管理层,传统T+1报表模式已无法满足精益改善需求;
3. 数据资产服务化场景:业务部门需要自助取用高质量数据做分析和决策,IT部门需从“数据搬运工”转型为“数据服务提供者”。
选型提示:不同企业所处的数字化转型阶段和数据治理成熟度差异较大。根据《江苏省制造业领域面向人工智能的数据治理工作参考指引》,企业可依据自身情况对照数据治理入门、基础、进阶三个等级,选择适配自身阶段的数据治理工具。建议先明确当前处于“打通数据孤岛”还是“建立数仓标准”阶段,再进入精细化产品评估,避免从“工具堆砌”直接跳到完美主义陷阱。
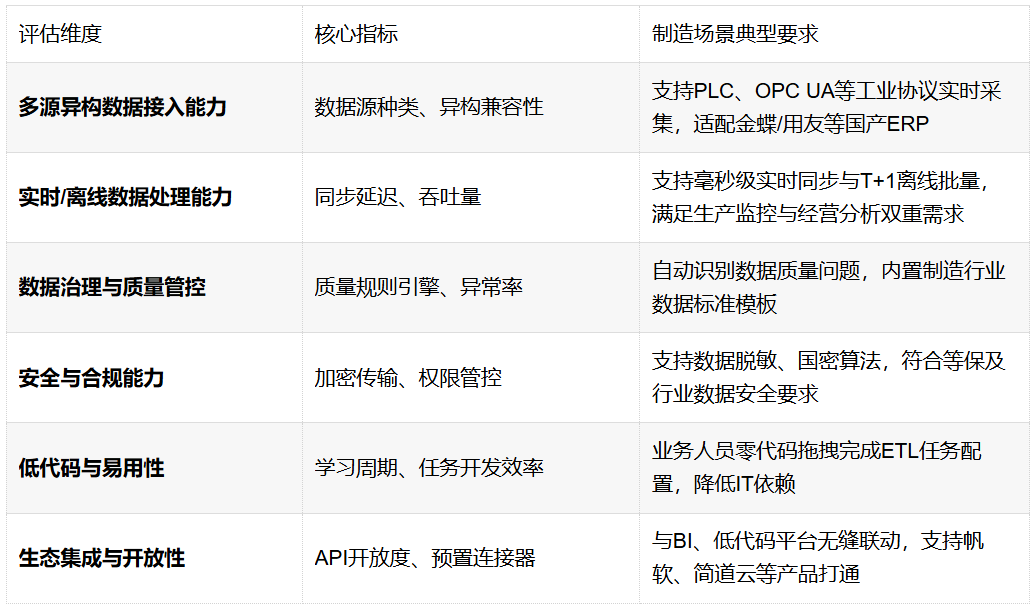
二、数据治理工具选型的6大核心维度
综合IDC、Gartner及中国软件评测中心等机构的评估方法论,我们将数据治理工具的评估体系概括为六大核心维度,覆盖从技术能力到业务价值的完整链条:
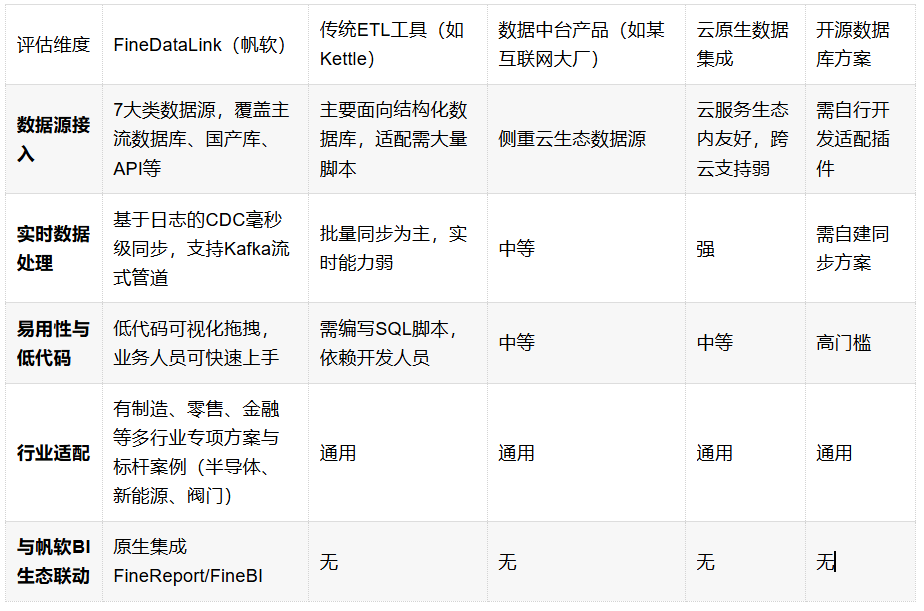
三、5款主流数据治理代表性产品横向对标
四、五大产品深度解析
(一)FineDataLink(帆软)
FineDataLink是帆软旗下的一站式数据集成平台,定位为低代码/高时效的企业级ETL工具,面向异构数据源实时同步、数据清洗、API发布等场景。
核心优势:
● 多源异构数据采集:支持MySQL、Oracle、SQL Server等关系型数据库,Hive、ClickHouse等大数据平台,MongoDB、Redis等NoSQL,以及API、Kafka、FTP/SFTP等接口和文件,共7大类数据源;
● 实时数据集成:基于日志的CDC变更数据捕获技术,低成本实现毫秒级实时同步与备份;
● 低代码可视化操作:DAG流程驱动,通过拖拽配置完成数据同步、调度、治理任务,大幅降低开发门槛;
● 制造业专项落地:针对离散制造场景有专门的数据驱动精益管理解决方案;
● 帆软生态原生集成:与FineReport、FineBI、简道云无缝打通,形成“数据集成→分析→决策”的一体化链条。
制造/泛行业标杆案例:
● 苏州安特威阀门(年营收超9亿),利用FineDataLink构建实时数据仓库,整合ERP、MES、SQS、PLM等系统数据,报表查询达到秒级展现,已存储超4亿行数据;
● 宁德新能源(ATL),利用FineDataLink调度合并报表后台数据,财务团队无需加班,IT部门可将指标加工为组件让业务自助取用。
(二)传统ETL工具(以Kettle/Pentaho为代表)
● 定位:开源ETL工具,适合数据仓库建设与批量数据迁移
● 优势:免费轻量、社区活跃、图形化拖拽易上手
● 局限:实时CDC能力弱,集群高可用需手工部署,数据质量与血缘追溯功能薄弱
● 适用:技术团队健全、对实时性要求不高的中小企业
(三)数据中台产品(以阿里云DataWorks为代表)
● 定位:云原生一站式大数据开发与治理平台
● 优势:全链路覆盖,与MaxCompute等深度集成,开箱即用免运维
● 局限:强依赖阿里云生态,定价复杂,工业OT直连能力偏弱
● 适用:已使用阿里云技术栈的中大型企业
(四)云原生数据集成工具(以Apache SeaTunnel为代表)
● 定位:Apache顶级项目,分布式高性能数据集成平台
● 优势:支持百余种数据源,实时/批量一体,云原生架构弹性好
● 局限:复杂转换需借助外部引擎,侧重采集而非全链路治理
● 适用:海量异构数据、多云/混合云环境下的实时同步场景
(五)开源数据库/数据仓库方案(以Apache Doris为代表)
● 定位:MPP架构实时分析型数据库,主打极速查询
● 优势:亚秒级响应,兼容MySQL协议,存储成本低
● 局限:仅作为数仓底座,须配合ETL工具完成数据集成
● 适用:对查询性能要求极高、已有数据集成能力的团队
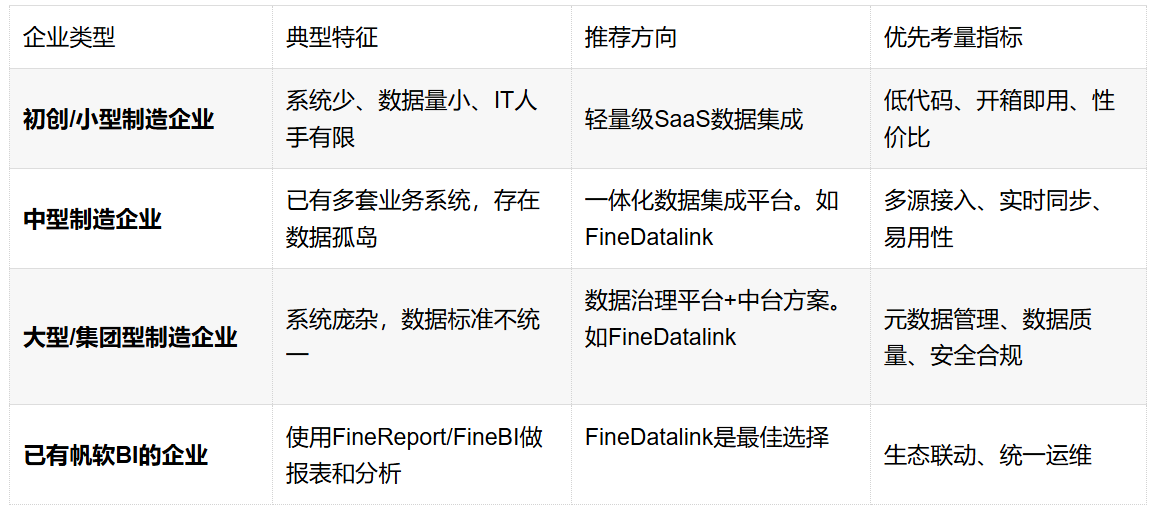
五、如何根据企业自身情况选择?
根据制造企业数据治理成熟度和业务需求,可参考以下选型路径:
六、总结与建议
根据IDC、Gartner等权威机构预测,中国数据治理平台市场规模正以近30%的年复合增长率高速增长,AI原生治理、信创适配、资产化运营已成为行业三大核心趋势。从制造企业实际来看,问题的核心往往不在于报表展现能力,而在于底层数据能否被“采得到、集得通、管得好”。选择数据治理工具时,建议遵循以下步骤:
1. 痛点诊断:明确当前最大阻力是“数据采不全”“实时传不了”还是“口径管不住”;
2. POC验证:选取3-5家候选产品,在1-2条产线或1个核心业务域进行真实数据测试,重点验证多源异构数据接入时效和稳定性;
3. 综合评估:结合技术能力、易用性、生态协同、成本及售后支持做综合评分;
4. 小步快跑:先从高频、低风险的业务场景切入,验证链路稳定后再逐步扩展。
对于正在使用或计划引入帆软FineReport、FineBI的制造企业,FineDataLink凭借其低代码优势、实时同步能力和与帆软生态的原生联动,是一个值得重点评估的“数据底座型”工具。建议通过POC(概念验证)测试,在真实业务环境中验证其能否有效打通您的ERP-MES数采链路、消除数据孤岛。