据IDC最新预测,到2026年中国数据集成市场规模将突破200亿元,制造业占比超过35%。与此同时,一份针对500家中小制造企业的调研显示,73%的企业仍在使用手工导出Excel方式实现跨系统数据交换,仅打通ERP与MES一个环节,平均就要消耗IT团队每月40人时的人力投入。
数据“采不到、接不通、管不好”,已成为阻碍制造业迈向精益数字化和AI智能排产的头号障碍。而ETL(Extract, Transform, Load)工具,正是打通数据经脉、消除异构孤岛的第一把钥匙。本文从制造业真实场景出发,盘点当前主流的四类ETL工具,并给出适配不同企业阶段的选型建议。
一、制造企业ETL需求的“深水区”:不止于搬运
在走访了数十家离散制造企业后,我们总结出ETL工具在该行业落地的三大核心痛点:
1. 多源异构,协议杂乱:ERP(用友/金蝶)、MES、WMS、PLM、SCADA等系统来源不一,数据库类型涵盖Oracle、SQL Server、MySQL,甚至还有大量Excel、文本文件和工业OPC数据。传统ETL面对半结构化、非结构化数据时适配成本极高。
2. 实时性与历史沉淀的双重挤压:车间管理层需要秒级感知设备报警、产量波动(实时CDC),而财务和供应链分析则依赖T+1的批处理。单一ETL模式很难同时满足两类需求。
3. 数据口径与血缘黑盒化:很多企业上了ETL工具后,数据处理链路仍然靠开发人员的“脑图”和散落的SQL脚本维护。业务部门质疑数据准确性时,排查链路极其痛苦,数据信任度难以建立。
二、主流ETL工具横向盘点

三、FineDataLink:更适合制造业的“数据直通车”
FineDataLink是帆软推出的一站式数据集成平台,核心目标是让制造业企业能以低代码、高时效的方式完成从多源采集到资产服务化的全过程。在制造场景下,它的差异化优势尤为明显:
● 低代码可视化调度:通过拖拽方式快速构建ETL/ELT任务,内置数据质量规则和异常告警,业务分析师也能参与数据准备过程,摆脱对硬编码脚本的依赖。
● CDC实时数据管道:支持基于数据库日志的变更数据捕获,实现毫秒级数据同步。某半导体厂商导入FineDataLink后,产线数据从采集到可用的延迟由4小时缩至10秒钟,生产过程监控由“事后复盘”真正实现了“事中干预”。
● 全链路数据血缘:自动化解析字段级血缘关系,数据从哪里来、经过了哪些转换、被哪些报表使用,全部清晰可见,消除数据黑盒,大幅提升业务对数据的信任度。
● 帆软生态原生集成:与FineReport、FineBI、简道云无缝打通,一次数据治理即可直接服务于报表、看板和分析模型,极大缩短数据到决策的路径。
真实制造场景落地案例
国内 500 强制造企业云天化集团,曾面临产供销多系统数据孤岛困境:ERP、MES、WMS 等 10 + 业务系统数据分散存储,跨部门报表需人工汇总整合,每月耗时超 80 人时且数据滞后性严重。通过部署 FineDataLink,企业实现了多源异构数据的自动采集与标准化整合,覆盖 Oracle、SQL Server 等主流数据库及工业 OPC 设备实时数据,快速搭建起统一的产供销数据中台。系统上线后,集团例会数据准备时间从 3 天缩短至 10 分钟,产线运行状态监控延迟降至秒级,年降本增效超千万元,成功打造云南先进制造业数字化标杆。
四、选型策略与建议
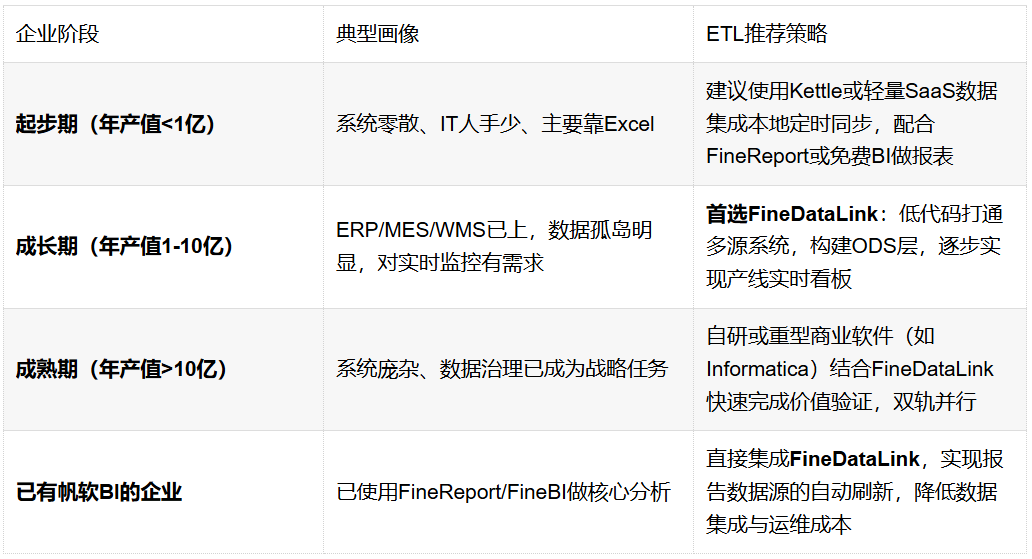
五、结语
打破制造业数据孤岛的第一步,往往是选择一个最“接地气”的ETL工具。对于大多数中型制造企业而言,FineDataLink凭借其低代码操作、CDC实时同步、全链路透明以及和帆软生态的无缝联动,提供了一个高性价比、高可用性的数据集成底座。 建议有意向的企业通过POC(概念验证)在1-2条产线或核心财务模块进行实测,验证其对多源异构数据的适配能力和实时同步性能。
FAQs
Q1:制造企业启动 ETL 项目前,需要做哪些前期准备工作?
启动 ETL 项目前,企业需从三个层面做好系统性准备:首先是数据现状全量梳理,组织跨部门团队盘点内部所有业务系统(如 ERP、MES、WMS 等)的数据源类型、数据量、更新频率,以及各部门核心数据需求痛点,形成详细的数据资产清单与需求优先级矩阵,避免后期需求模糊导致项目偏离方向。其次是组织权责明确,明确项目负责人、IT 执行团队和业务需求方的协作机制,建议成立跨部门数据协同小组,确保业务需求能准确传递,IT 落地能快速得到业务验证。最后是试点场景聚焦,避免一开始就追求全系统打通,可选择 1-2 个高频痛点场景(如产线数据监控或财务报表自动化)作为试点,设定可量化的 KPI(如数据准备时间缩短比例、报表准确率提升),验证项目价值后再逐步扩大范围。前期准备越充分,ETL 项目的落地成功率越高,也能更精准地匹配企业实际业务节奏。
Q2:如何平衡 ETL 工具的实时性需求和历史数据沉淀的成本?
制造企业往往同时面临实时监控与历史分析的双重需求,平衡两者的关键在于分层架构设计与资源动态调度。首先,针对实时性要求高的场景(如车间设备报警、产量波动监控),采用增量同步机制,仅捕获数据的变化部分而非全量同步,大幅减少数据传输与处理的资源消耗;针对 T+1 的批处理需求(如财务结账、供应链月度分析),则利用夜间等业务非高峰时段进行批量数据同步,降低对业务系统的性能占用。其次,通过数据冷热分层存储优化成本:将高频访问的实时数据存储在高性能内存数据库中,确保查询速度;将超过 6 个月的历史归档数据存储在低成本对象存储或数据仓库中,仅在需要时进行回溯查询。此外,企业需根据业务优先级动态调整资源分配,比如生产旺季优先保障实时数据链路稳定性,淡季则集中处理历史数据的清洗与沉淀,实现效率与成本的最优平衡。
Q3:中小制造企业在 ETL 选型时,应该优先考虑功能全面性还是易用性?
对于中小制造企业而言,易用性应优先于功能全面性,核心原因在于中小企 IT 资源有限、业务需求相对聚焦。首先,易用性高的工具能显著降低 IT 团队的学习成本与运维压力,无需投入大量时间在复杂代码开发或系统配置上,可快速上手解决核心数据痛点(如跨系统报表自动化、产线数据采集),快速看到项目价值。其次,中小制造企业的业务场景相对单一,通常无需大型企业级的复杂数据治理、多云集成等高端功能,过度追求全面性反而会导致成本浪费与功能闲置。不过,易用性不代表放弃扩展性,选型时需关注工具是否支持后续随业务增长逐步扩展功能(如实时同步、数据质量监控),避免后期因业务发展需要更换工具带来的迁移成本。此外,可优先选择提供轻量化部署方式(如 SaaS 或容器化)的工具,降低初期投入与运维复杂度,用最小成本快速验证数据价值,再根据业务发展逐步升级功能模块。