 全部案例
全部案例
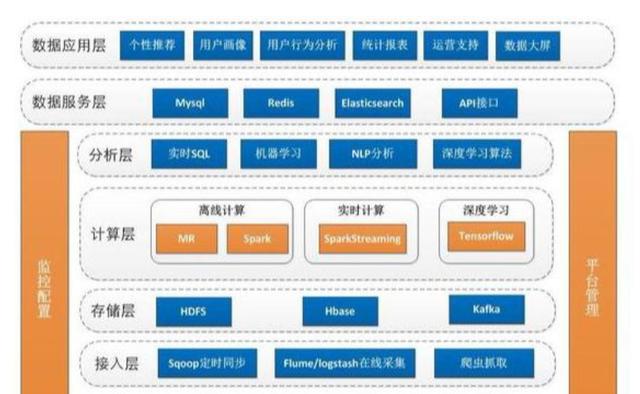
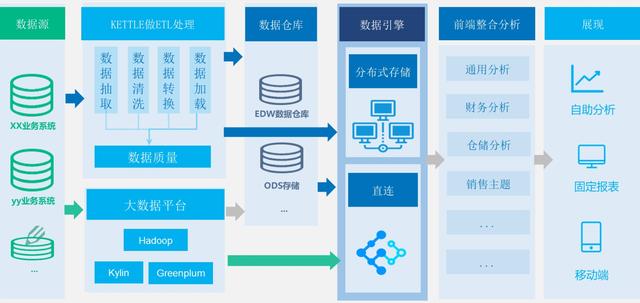
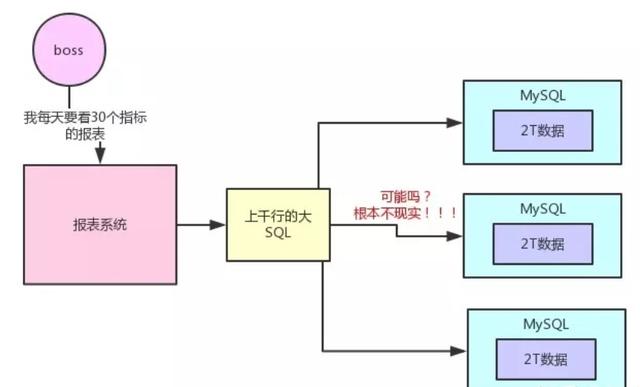
 传统的主机计算模式在海量数据面前,显得弱鸡。造价非常昂贵,同时技术上也无法满足高性能的计算,smp架构难于扩展,在独立主机的cpu计算和io吞吐上,都没办法满足海量数据计算的需求。分布式存储和分布式计算正是解决这一问题的关键,不管是后面的MapReduce计算框架还是MPP计算框架,都是在这一背景下产生的。
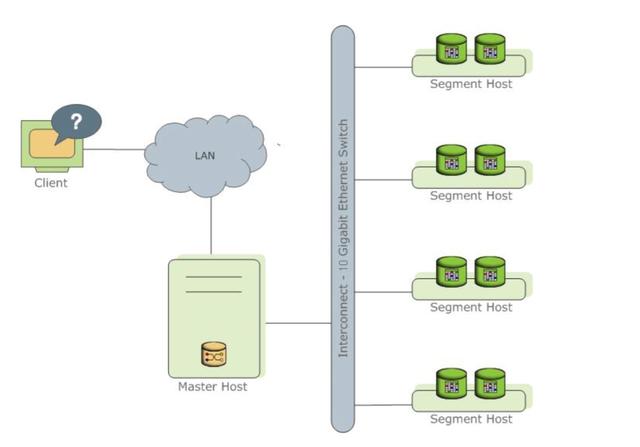
greenplum的数据库引擎是基于postgresql的,并且通过Interconnnect神器实现了对同一个集群中多个Postgresql实例的高效协同和并行计算。
4.hadoop分布式系统架构
关于hadoop,已经火的要爆炸了,greenplum的开源跟它也是脱不了关系的。有着高可靠性、高扩展性、高效性、高容错性的口碑。在互联网领域有非常广泛的运用,雅虎、facebook、百度、淘宝等等等等。
hadoop生态体系非常庞大,各公司基于hadoop所实现的也不仅限于数据分析,也包括机器学习、数据挖掘、实时系统等。
传统的主机计算模式在海量数据面前,显得弱鸡。造价非常昂贵,同时技术上也无法满足高性能的计算,smp架构难于扩展,在独立主机的cpu计算和io吞吐上,都没办法满足海量数据计算的需求。分布式存储和分布式计算正是解决这一问题的关键,不管是后面的MapReduce计算框架还是MPP计算框架,都是在这一背景下产生的。
greenplum的数据库引擎是基于postgresql的,并且通过Interconnnect神器实现了对同一个集群中多个Postgresql实例的高效协同和并行计算。
4.hadoop分布式系统架构
关于hadoop,已经火的要爆炸了,greenplum的开源跟它也是脱不了关系的。有着高可靠性、高扩展性、高效性、高容错性的口碑。在互联网领域有非常广泛的运用,雅虎、facebook、百度、淘宝等等等等。
hadoop生态体系非常庞大,各公司基于hadoop所实现的也不仅限于数据分析,也包括机器学习、数据挖掘、实时系统等。
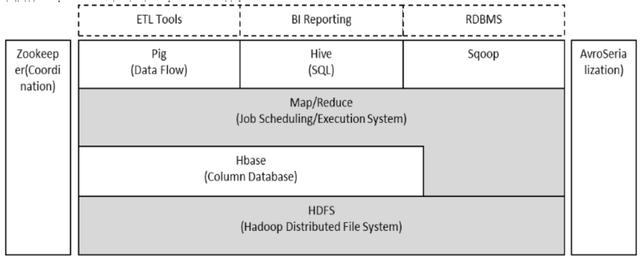 当企业数据规模达到一定的量级,我想hadoop是各大企业的首选方案,到达这样一个层次的时候,我想企业所要解决的也不仅是性能问题,还会包括时效问题、更复杂的分析挖掘功能的实现等。非常典型的实时计算体系也与hadoop这一生态体系有着紧密的联系。
近些年来hadoop的易用性也有了很大的提升,sql-on-hadoop技术大量涌现,包括hive、impala、spark-sql等。尽管其处理方式不同,但普遍相比于原始基于文件的Mapreduce,不管是性能还是易用性,都是有所提高的。也因此对mpp产品的市场产生了压力。
对于企业构建数据平台来说,hadoop的优势与劣势非常明显:它的大数据的处理能力、高可靠性、高容错性、开源性以及低成本(为什么说低成本,要处理同样规模的数据,换一个其他方案试试呢)。缺点也就是他的体系的复杂,技术门槛较高(能搞定hadoop的公司规模一般都不小了)。
关于hadoop的优缺点对于公司的数据平台选型来说,影响已经不大了。需要上hadoop的时候,也没什么其它的方案好选择(要么太贵,要么不行),没到达这个数据量的时候,也没人愿意碰这东西。总之,不要为了大数据而大数据。
当企业数据规模达到一定的量级,我想hadoop是各大企业的首选方案,到达这样一个层次的时候,我想企业所要解决的也不仅是性能问题,还会包括时效问题、更复杂的分析挖掘功能的实现等。非常典型的实时计算体系也与hadoop这一生态体系有着紧密的联系。
近些年来hadoop的易用性也有了很大的提升,sql-on-hadoop技术大量涌现,包括hive、impala、spark-sql等。尽管其处理方式不同,但普遍相比于原始基于文件的Mapreduce,不管是性能还是易用性,都是有所提高的。也因此对mpp产品的市场产生了压力。
对于企业构建数据平台来说,hadoop的优势与劣势非常明显:它的大数据的处理能力、高可靠性、高容错性、开源性以及低成本(为什么说低成本,要处理同样规模的数据,换一个其他方案试试呢)。缺点也就是他的体系的复杂,技术门槛较高(能搞定hadoop的公司规模一般都不小了)。
关于hadoop的优缺点对于公司的数据平台选型来说,影响已经不大了。需要上hadoop的时候,也没什么其它的方案好选择(要么太贵,要么不行),没到达这个数据量的时候,也没人愿意碰这东西。总之,不要为了大数据而大数据。
 当然,要明确数据平台的建设目的,哪里是那么容易的,初衷与讨论后确认的目标或许是不一致的。
公司要搭建一个数据平台的初衷可能很简单,只是为了减轻业务系统的压力,将数据拉出来后再分析,如果目的真的就这么单纯,还真的没有必要大动干戈了。
如果是独立系统的话,直接将业务系统的数据库复制出来一份就好了;如果是多系统,快速建模,直接用finebi或者finereport接入进去就能实现数据的可视化与olap分析。
当然,要明确数据平台的建设目的,哪里是那么容易的,初衷与讨论后确认的目标或许是不一致的。
公司要搭建一个数据平台的初衷可能很简单,只是为了减轻业务系统的压力,将数据拉出来后再分析,如果目的真的就这么单纯,还真的没有必要大动干戈了。
如果是独立系统的话,直接将业务系统的数据库复制出来一份就好了;如果是多系统,快速建模,直接用finebi或者finereport接入进去就能实现数据的可视化与olap分析。
 但是,既然已经决定要将数据平台独立出来了,就不再多考虑一点吗?多个系统的数据,不趁机梳理整合一下?当前只有分析业务数据的需求,以后会不会考虑到历史数据呢?这种敏捷的方案能够支撑明年、后年的需求吗?
任何公司要搭建数据平台,都不是一件小事,多花一两个月实施你可能觉得累,多花一周两周的时间,认真的思考一下总可以的吧。雷军不是说过这样一句话:不能以战术上的勤奋,掩盖战略上的懒惰。
2.数据量:根据公司的数据规模选择合适的方案,这里说多了都是废话。
3.成本:包括时间成本和金钱,不必多说。但是这里有一个问题想提一下,发现很多公司,要么不上数据平台,一旦有了这样的计划,就恨不得马上把平台搭出来用起来,时间成本不肯花,这样的情况很容易考虑欠缺,也容易被数据实施方忽悠。
但是,既然已经决定要将数据平台独立出来了,就不再多考虑一点吗?多个系统的数据,不趁机梳理整合一下?当前只有分析业务数据的需求,以后会不会考虑到历史数据呢?这种敏捷的方案能够支撑明年、后年的需求吗?
任何公司要搭建数据平台,都不是一件小事,多花一两个月实施你可能觉得累,多花一周两周的时间,认真的思考一下总可以的吧。雷军不是说过这样一句话:不能以战术上的勤奋,掩盖战略上的懒惰。
2.数据量:根据公司的数据规模选择合适的方案,这里说多了都是废话。
3.成本:包括时间成本和金钱,不必多说。但是这里有一个问题想提一下,发现很多公司,要么不上数据平台,一旦有了这样的计划,就恨不得马上把平台搭出来用起来,时间成本不肯花,这样的情况很容易考虑欠缺,也容易被数据实施方忽悠。
 场景b:要搭建公司级的数据中心,打通各系统之间的数据。非常明显的,需要搭建一个数据仓库。这时就需要进一步考虑公司数据的量级了,如果是小数据量,TB级以下,那么在传统数据库中建这样一个数据仓库就可以了,如果数据量达到几十上百TB,或者可见的在未来几年内数据会达到这样一个规模,可以将仓库搭在greenplum中。
这种场景应该是适用于大部分公司,对于大部分企业来说,数据量都不会PB级别,更多的是在TB级以下。
场景c:公司数据爆发式增长,原有的数据平台无法承担海量数据的处理,那么就建议考虑hadoop这种大数据平台了。它一定是公司的数据中心,这样一个角色,仓库是少不了的,可以将原来的仓库直接搬到hive中去。
这种数据量比较大的情况要怎样呈现,因为hive的性能较差,它的即席查询可以接impala,也可以接greenplum,因为impala的并发量不是那么高,而greenplum正好有它的外部表(也就是greenplum创建一张表,表的特性叫做外部表,读取的内容是hadoop的hive里的),正好和hadoop完美的融合(当然也可以不用外部表)。
场景d:这个是后面补充的,当公司原本有一个数据仓库,但历史数据了堆积过多,分析性能下降,要怎么办?两个方案可以考虑,比较长远的,可以将仓库以及数据迁移到greenplum中,形成一个新的数据平台,一个独立的数据平台,可以产生更多的可能性;比较快速的,是可以将类似finecube那种敏捷型数据产品接入原来的仓库,这样来提升数据的处理性能,满足分析的要求。
场景b:要搭建公司级的数据中心,打通各系统之间的数据。非常明显的,需要搭建一个数据仓库。这时就需要进一步考虑公司数据的量级了,如果是小数据量,TB级以下,那么在传统数据库中建这样一个数据仓库就可以了,如果数据量达到几十上百TB,或者可见的在未来几年内数据会达到这样一个规模,可以将仓库搭在greenplum中。
这种场景应该是适用于大部分公司,对于大部分企业来说,数据量都不会PB级别,更多的是在TB级以下。
场景c:公司数据爆发式增长,原有的数据平台无法承担海量数据的处理,那么就建议考虑hadoop这种大数据平台了。它一定是公司的数据中心,这样一个角色,仓库是少不了的,可以将原来的仓库直接搬到hive中去。
这种数据量比较大的情况要怎样呈现,因为hive的性能较差,它的即席查询可以接impala,也可以接greenplum,因为impala的并发量不是那么高,而greenplum正好有它的外部表(也就是greenplum创建一张表,表的特性叫做外部表,读取的内容是hadoop的hive里的),正好和hadoop完美的融合(当然也可以不用外部表)。
场景d:这个是后面补充的,当公司原本有一个数据仓库,但历史数据了堆积过多,分析性能下降,要怎么办?两个方案可以考虑,比较长远的,可以将仓库以及数据迁移到greenplum中,形成一个新的数据平台,一个独立的数据平台,可以产生更多的可能性;比较快速的,是可以将类似finecube那种敏捷型数据产品接入原来的仓库,这样来提升数据的处理性能,满足分析的要求。
 然而在后期突然意识到,工具所解决的,仅仅是在技术层面上简化了工具的使用的复杂性,把etl和数据集市封装在一起,并且提高了数据的性能,但是并没有从业务层面上实现数据的建模,很多细节问题无法处理。
虽然敏捷开发非常诱人,如果业务系统简单,或者只需要分析当前状态的业务数据,不需要公司级的数据中心,那么确实是一个非常好的方案。然而这些问题还没有考虑清楚,对敏捷产品有了过高的期望,后面是会遇到些麻烦的。
除此之外,可能还会有为了大数据而大数据的,但是这些我在实际的工作中还没有遇到。
最后总结一下,企业选择数据平台的方案,有着不同的原因,要合理的选型,既要充分的考虑搭建数据平台的目的,也要对各种方案有着充分的认识。
仅从个人的角度,对于数据层面来说,还是倾向于一些灵活性很强的方案的,因为数据中心对于公司来说太重要了,我更希望它是透明的,是可以被自己完全掌控的,这样才有能力实现对数据中心更加充分的利用。因为,我不知道未来需要它去承担一个什么样的角色。
ps:数据平台的建设,是一个不小的项目,实施周期过长,会不会途中夭折?这锅谁都不想背,这样的项目,怎样才能迭代起来,逐步实施逐步投放?
然而在后期突然意识到,工具所解决的,仅仅是在技术层面上简化了工具的使用的复杂性,把etl和数据集市封装在一起,并且提高了数据的性能,但是并没有从业务层面上实现数据的建模,很多细节问题无法处理。
虽然敏捷开发非常诱人,如果业务系统简单,或者只需要分析当前状态的业务数据,不需要公司级的数据中心,那么确实是一个非常好的方案。然而这些问题还没有考虑清楚,对敏捷产品有了过高的期望,后面是会遇到些麻烦的。
除此之外,可能还会有为了大数据而大数据的,但是这些我在实际的工作中还没有遇到。
最后总结一下,企业选择数据平台的方案,有着不同的原因,要合理的选型,既要充分的考虑搭建数据平台的目的,也要对各种方案有着充分的认识。
仅从个人的角度,对于数据层面来说,还是倾向于一些灵活性很强的方案的,因为数据中心对于公司来说太重要了,我更希望它是透明的,是可以被自己完全掌控的,这样才有能力实现对数据中心更加充分的利用。因为,我不知道未来需要它去承担一个什么样的角色。
ps:数据平台的建设,是一个不小的项目,实施周期过长,会不会途中夭折?这锅谁都不想背,这样的项目,怎样才能迭代起来,逐步实施逐步投放?
比如,目前主流的软件——FineDataLink,它小到数据库对接、API对接、行列转换、参数设置,大到任务调度、运维监控、实时数据同步、数据服务API分享,应有尽有,功能很强大。最重要的是,因为这个工具,整个公司的数据架构都可以变得规范。而且它是java编写的,类流程图式的ETL开发模式,上手都很简单:数据对接、任务复用简直都是小case,大大降低了数据开发的门槛。在企业中被关注最多的任务运维,FineDataLink大运维平台,支持文件夹式开发模式,报错任务可一键直达修改,报错优化清晰易懂;通过权限控制,保障系统安全。


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号



