 全部案例
全部案例
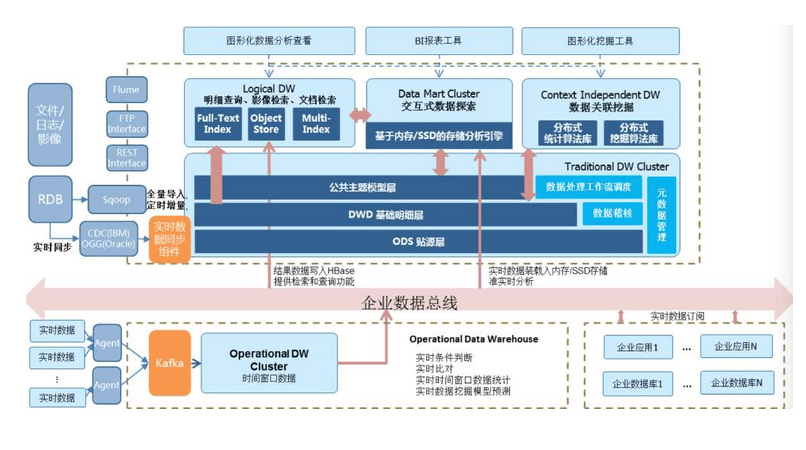 数仓的假设既然都是采用的维度建模,那么其设计思想必然是自下而上的进行建设,与架构进行类比,也就是先做好子模块,最后做顶层设计。
但如果设计者不熟悉对应的领域模型,一旦业务上发生了变动,一张核心表动辄几百张的引用,会让重构的工作变得困难无比。
强如阿里,会做一些更进一步的工作,比如模型的健康分,看看你的存储成本有多少、计算成本有多少、生命周期是不是合理、代码规范有没有避免全表扫描,等等。但这些工作只能发现一些常规的问题,也依然需要进行人工治理,不仅效率上没有得到提高,每天推送的邮件也会让你产生心烦。
投入多少人,投入多少时间,终归是解决了一时的问题,而非长远。
数仓的假设既然都是采用的维度建模,那么其设计思想必然是自下而上的进行建设,与架构进行类比,也就是先做好子模块,最后做顶层设计。
但如果设计者不熟悉对应的领域模型,一旦业务上发生了变动,一张核心表动辄几百张的引用,会让重构的工作变得困难无比。
强如阿里,会做一些更进一步的工作,比如模型的健康分,看看你的存储成本有多少、计算成本有多少、生命周期是不是合理、代码规范有没有避免全表扫描,等等。但这些工作只能发现一些常规的问题,也依然需要进行人工治理,不仅效率上没有得到提高,每天推送的邮件也会让你产生心烦。
投入多少人,投入多少时间,终归是解决了一时的问题,而非长远。
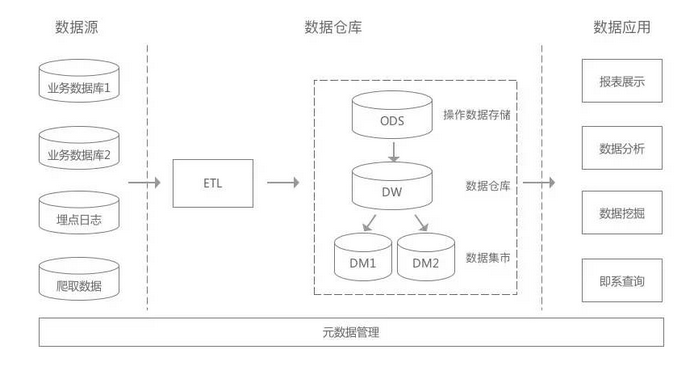 因此,换个思路考虑问题,当业务高速发展时,数仓势必要跟着跑,不然业务都跪了,数仓又有何用。但业务通常不会一直处于高速发展的阶段,就像长跑一样,总有跑跑停停的时候,因此如果我们遵循一定的做事方法,流程上多一点步骤,那么就会极大的延缓数仓治理的问题。
即不追求长久的问题解决,而以一段时间内的稳定为目标,比如一年。当业务已经发展到比较稳定的阶段,再回过头来做治理,既能够避免因为业务变动而影响模型重构,也可以节省大家的精力和压力,就不失为一种解决思路了。
完美的解决方案通常不存在,退而求其次是大多数人的选择。当技术无法解决问题时,不妨用另类思路去解决。
因此,换个思路考虑问题,当业务高速发展时,数仓势必要跟着跑,不然业务都跪了,数仓又有何用。但业务通常不会一直处于高速发展的阶段,就像长跑一样,总有跑跑停停的时候,因此如果我们遵循一定的做事方法,流程上多一点步骤,那么就会极大的延缓数仓治理的问题。
即不追求长久的问题解决,而以一段时间内的稳定为目标,比如一年。当业务已经发展到比较稳定的阶段,再回过头来做治理,既能够避免因为业务变动而影响模型重构,也可以节省大家的精力和压力,就不失为一种解决思路了。
完美的解决方案通常不存在,退而求其次是大多数人的选择。当技术无法解决问题时,不妨用另类思路去解决。
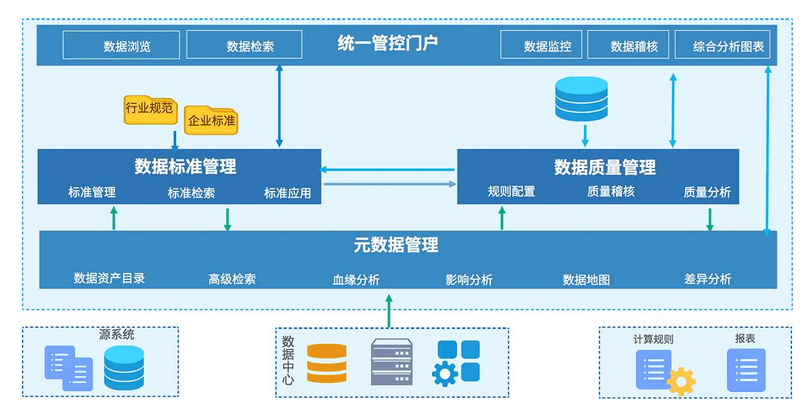 最后,定义好一致性的维度,即DIM。通常是静态的信息,如果存在动态可变的属性,还是放到DWD比较合适。
从这里开始,每位研发同学,都可以掌握维度建模的核心思想,通常公共层建设好之后,应该是变动极其小的,为了避免设计不好导致的后续维护问题,模型一定要有评审,即便是忙,也至少要找一个人帮忙进行CodeReview。
根据这些建模方法,我们就可以愉快的进行ADS层的业务开发了。
最后,定义好一致性的维度,即DIM。通常是静态的信息,如果存在动态可变的属性,还是放到DWD比较合适。
从这里开始,每位研发同学,都可以掌握维度建模的核心思想,通常公共层建设好之后,应该是变动极其小的,为了避免设计不好导致的后续维护问题,模型一定要有评审,即便是忙,也至少要找一个人帮忙进行CodeReview。
根据这些建模方法,我们就可以愉快的进行ADS层的业务开发了。
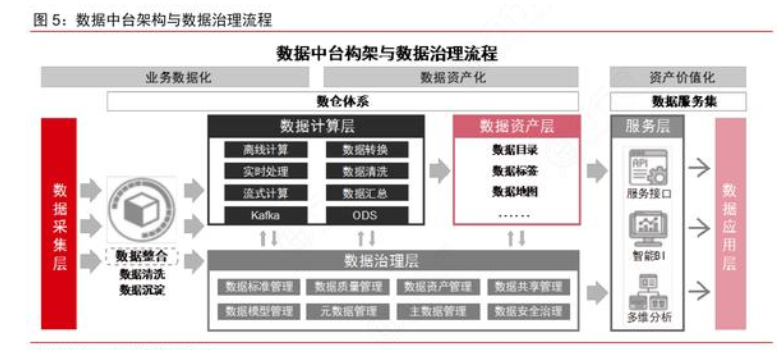
 例如,我们可以检测重复开发的表有哪些,通过表名相似性/字段相似性/数据量相似性等,估算两两之间的相似情况,如果相似程度90%以上,通常它们是可以合并的。
再者,我们可以使用更高阶的算法,比如计算两张表的主键与上下游引用,如果主键相似,且上下游表高度重合,那么这样的两张表也是可以合并的。准确来讲,自动规则,体现了我们对于数仓模型的理解程度。
基于价值衡量:治理也要有优先级,优先治理高价值的场景,或者寻找低价值的重构点,都是投入侧重点的最重要因素。比如,A表只有一个下游,占用了1TB的空间,而B表有1000个下游,占用了1GB的空间,是不是意味着B表价值远大于A表?
不见得,只要下游的收益,大于存储这些数据的成本,就是有用的。因此只根据收益和成本,来衡量数据表的价值,容易产生极端。这里如果有算法的同学能够接入,做一些类似于C-V模型的公式,找出异常点,就能够相对准确的衡量价值。但这一点目前比较难以实现。
最后提一下工具的重要性。数据治理有一个很棘手的问题,我们发现了有问题的表,如何进行纠正?比如字段不同了要废弃,比如命名不规范要重新改,那么如果下游依赖过多,又涉及权限问题,基本上就算是无药可救的状态了。
这时候有一个工具,能够同步Hive解决命名问题,同步下游修改字段命名,以及将表的权限复制到新表中,就很有用。
例如,我们可以检测重复开发的表有哪些,通过表名相似性/字段相似性/数据量相似性等,估算两两之间的相似情况,如果相似程度90%以上,通常它们是可以合并的。
再者,我们可以使用更高阶的算法,比如计算两张表的主键与上下游引用,如果主键相似,且上下游表高度重合,那么这样的两张表也是可以合并的。准确来讲,自动规则,体现了我们对于数仓模型的理解程度。
基于价值衡量:治理也要有优先级,优先治理高价值的场景,或者寻找低价值的重构点,都是投入侧重点的最重要因素。比如,A表只有一个下游,占用了1TB的空间,而B表有1000个下游,占用了1GB的空间,是不是意味着B表价值远大于A表?
不见得,只要下游的收益,大于存储这些数据的成本,就是有用的。因此只根据收益和成本,来衡量数据表的价值,容易产生极端。这里如果有算法的同学能够接入,做一些类似于C-V模型的公式,找出异常点,就能够相对准确的衡量价值。但这一点目前比较难以实现。
最后提一下工具的重要性。数据治理有一个很棘手的问题,我们发现了有问题的表,如何进行纠正?比如字段不同了要废弃,比如命名不规范要重新改,那么如果下游依赖过多,又涉及权限问题,基本上就算是无药可救的状态了。
这时候有一个工具,能够同步Hive解决命名问题,同步下游修改字段命名,以及将表的权限复制到新表中,就很有用。


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号



