 全部案例
全部案例
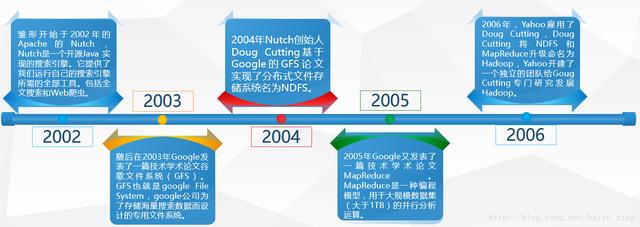
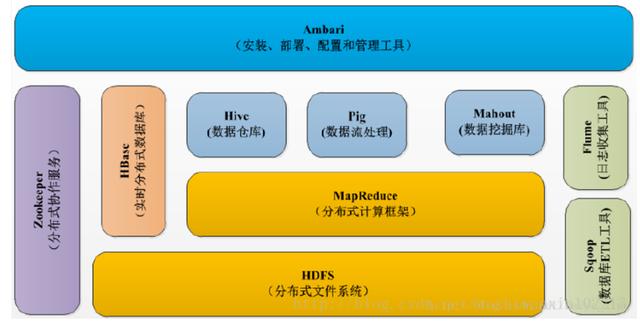 分析:Hadoop的核心组件分为:HDFS(分布式文件系统)、MapRuduce(分布式运算编程框架)、YARN(运算资源调度系统)
分析:Hadoop的核心组件分为:HDFS(分布式文件系统)、MapRuduce(分布式运算编程框架)、YARN(运算资源调度系统)
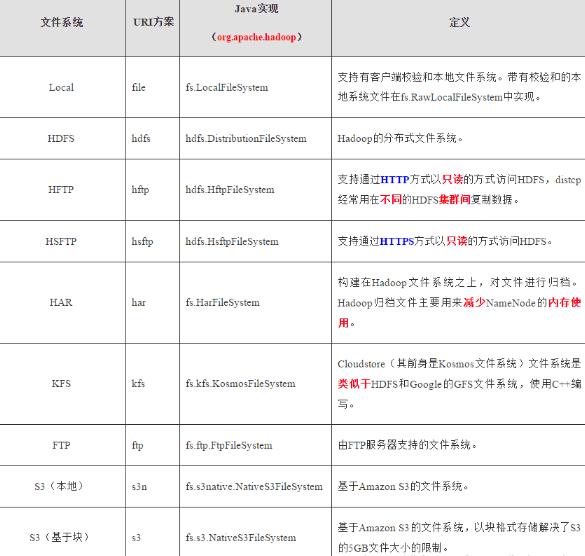
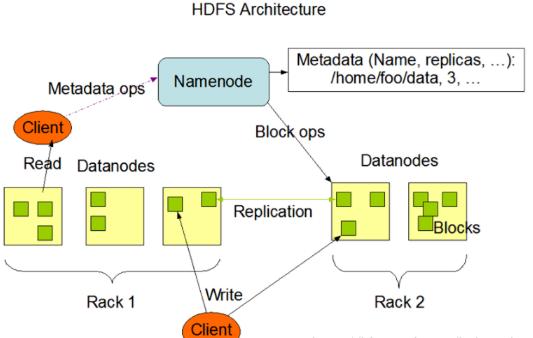
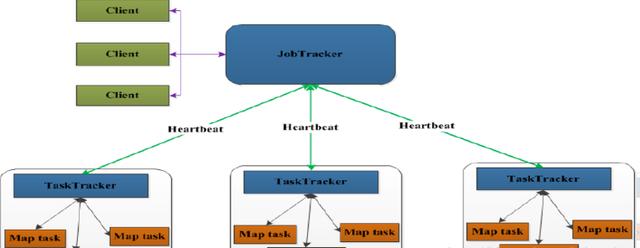 分析:
(1)JobTracker
JobTracker叫作业跟踪器,运行到主节点(Namenode)上的一个很重要的进程,是MapReduce体系的调度器。用于处理作业(用户提交的代码)的后台程序,决定有哪些文件参与作业的处理,然后把作业切割成为一个个的小task,并把它们分配到所需要的数据所在的子节点。
Hadoop的原则就是就近运行,数据和程序要在同一个物理节点里,数据在哪里,程序就跑去哪里运行。这个工作是JobTracker做的,监控task,还会重启失败的task(于不同的节点),每个集群只有唯一一个JobTracker,类似单点的NameNode,位于Master节点
(2)TaskTracker
TaskTracker叫任务跟踪器,MapReduce体系的最后一个后台进程,位于每个slave节点上,与datanode结合(代码与数据一起的原则),管理各自节点上的task(由jobtracker分配),
每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态,
Map Task:解析每条数据记录,传递给用户编写的map(),并执行,将输出结果写入本地磁盘(如果为map-only作业,直接写入HDFS)。
Reducer Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行。
分析:
(1)JobTracker
JobTracker叫作业跟踪器,运行到主节点(Namenode)上的一个很重要的进程,是MapReduce体系的调度器。用于处理作业(用户提交的代码)的后台程序,决定有哪些文件参与作业的处理,然后把作业切割成为一个个的小task,并把它们分配到所需要的数据所在的子节点。
Hadoop的原则就是就近运行,数据和程序要在同一个物理节点里,数据在哪里,程序就跑去哪里运行。这个工作是JobTracker做的,监控task,还会重启失败的task(于不同的节点),每个集群只有唯一一个JobTracker,类似单点的NameNode,位于Master节点
(2)TaskTracker
TaskTracker叫任务跟踪器,MapReduce体系的最后一个后台进程,位于每个slave节点上,与datanode结合(代码与数据一起的原则),管理各自节点上的task(由jobtracker分配),
每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态,
Map Task:解析每条数据记录,传递给用户编写的map(),并执行,将输出结果写入本地磁盘(如果为map-only作业,直接写入HDFS)。
Reducer Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行。
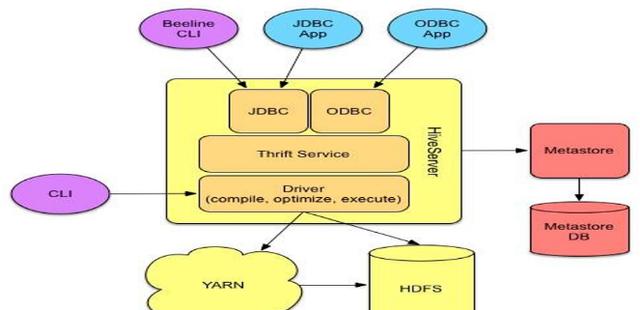 分析:Hive架构包括:CLI(Command Line Interface)、JDBC/ODBC、Thrift Server、WEB GUI、Metastore和Driver(Complier、Optimizer和Executor),这些组件分为两大类:服务端组件和客户端组件
分析:Hive架构包括:CLI(Command Line Interface)、JDBC/ODBC、Thrift Server、WEB GUI、Metastore和Driver(Complier、Optimizer和Executor),这些组件分为两大类:服务端组件和客户端组件
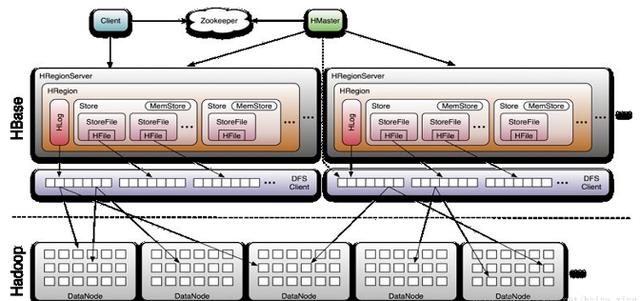
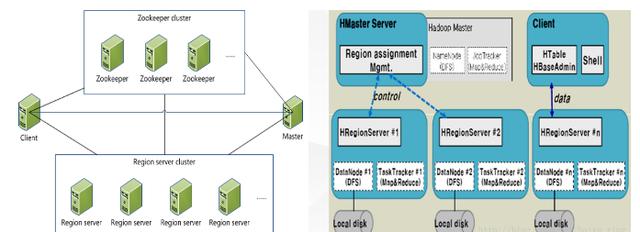 分析:从上图可以看出:Hbase主要由Client、Zookeeper、HMaster和HRegionServer组成,由Hstore作存储系统。
Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与 HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
Zookeeper
Zookeeper Quorum 中除了存储了 -ROOT- 表的地址和 HMaster 的地址,HRegionServer 也会把自己以 Ephemeral 方式注册到 Zookeeper 中,使得 HMaster 可以随时感知到各个HRegionServer 的健康状态。
分析:从上图可以看出:Hbase主要由Client、Zookeeper、HMaster和HRegionServer组成,由Hstore作存储系统。
Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与 HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
Zookeeper
Zookeeper Quorum 中除了存储了 -ROOT- 表的地址和 HMaster 的地址,HRegionServer 也会把自己以 Ephemeral 方式注册到 Zookeeper 中,使得 HMaster 可以随时感知到各个HRegionServer 的健康状态。
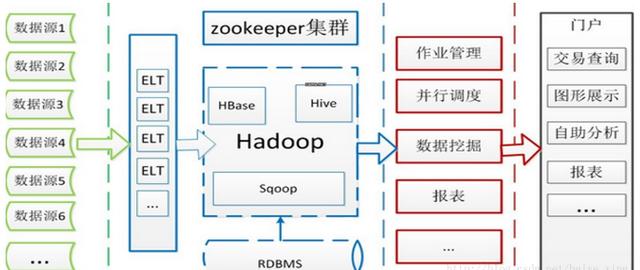
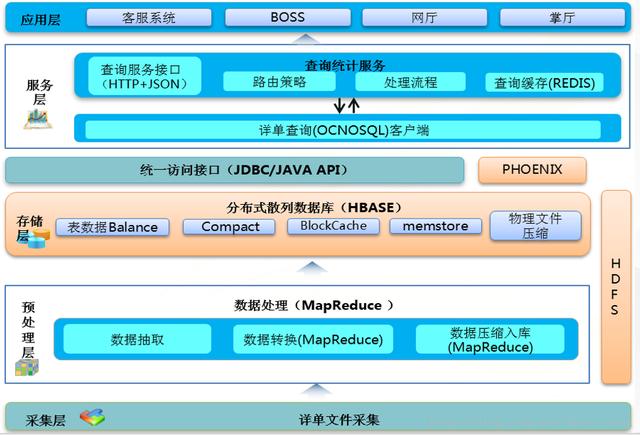 (2)流量查询系统总体流程
(2)流量查询系统总体流程
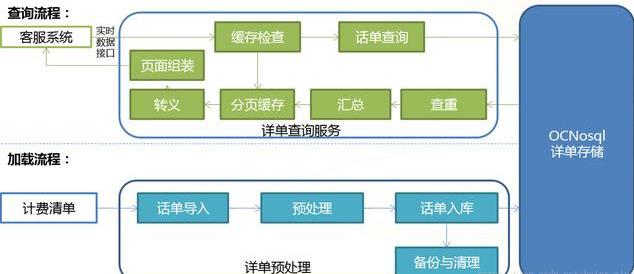 (3)流量查询系统数据预处理功能框架
(3)流量查询系统数据预处理功能框架
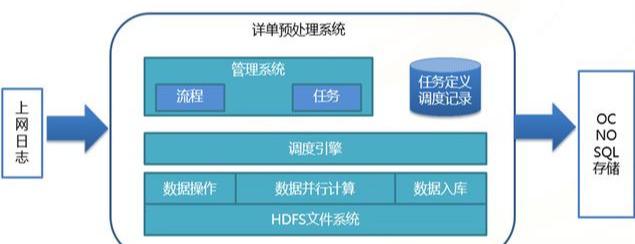 (4)流量查询系统数据预处理流程
(4)流量查询系统数据预处理流程
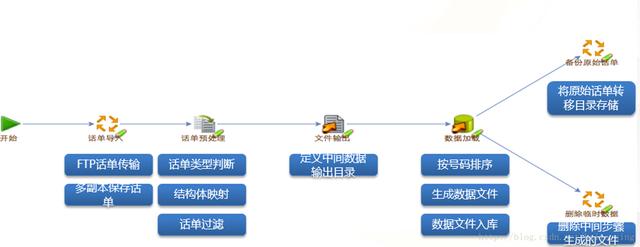 (5)流量查询NoSQL数据库功能框架
(5)流量查询NoSQL数据库功能框架
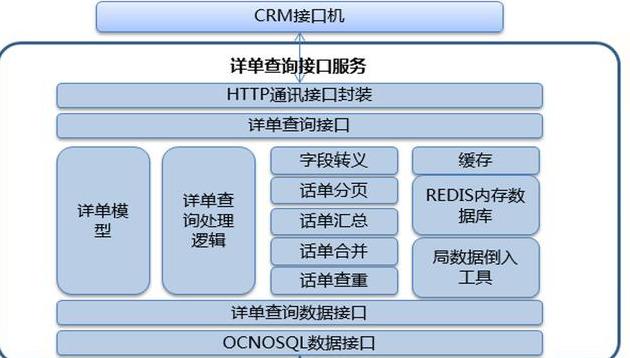
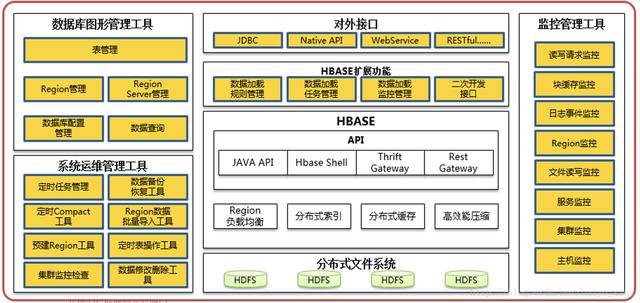 (6)流量查询服务功能框架
(6)流量查询服务功能框架
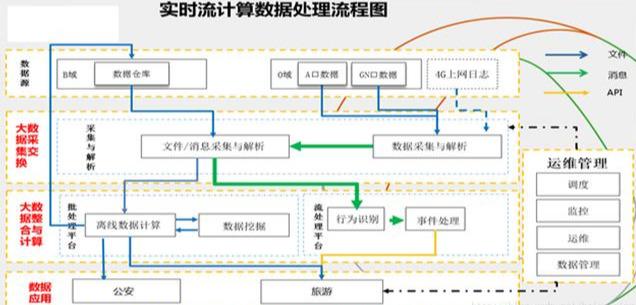
 (7)实时流计算数据处理流程图
(7)实时流计算数据处理流程图


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号



