 全部案例
全部案例
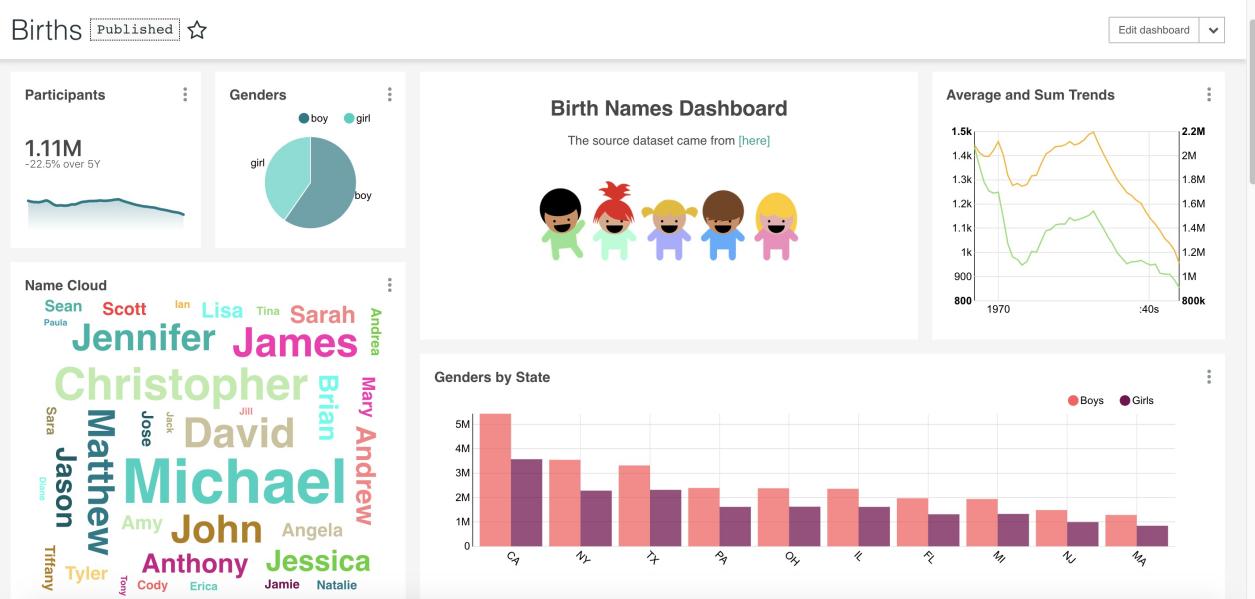 目前来说,个人体验下来,感觉有这些:
安装教程很繁琐,和装MySQL一样麻烦
仅支持单表获取,不支持表连接,计算速度取决于数据库的速度
有许多可视化选项,并且有多套基于经纬度的地理位置可视化方案
权限控制很细,下至每个功能键
遗憾的是,最大的问题是业务分析师的用户体验不是很好,数据可视化流程是为不同图形方案设置相应的参数,权限控制复杂。
各方面的具体情况如下:
1)数据源与数据管理
支持多种数据库:Athena、Redshift、Drill、Druid、Hive、Impala、Kylin、Spark SQL、BigQuery、Pinot、ClickHouse、Google Sheets、Greenplum、IBM Db2、MySQL、Oracle、PostgreSQL、Presto、Snowflake、SQLite、SQL Server、Teradata、Vertica、支持上传本地CSV文件
对于数据表模型的管理,可以设置字段类型、维度/是否过滤/是否制作时间列、二次处理字段、统计指标
图表可用的数据表必须从数据库中逐个添加(可以在SQL工具箱中看到它们),这不是很方便
深度支持durid
2)chart单图&dashboard看板
单图制作流程:选择数据源(表或视图)->选择图表类型->设置图表参数(指标/维度/过滤条件)。只能从数据表列表页选择数据源。进入分析页面后,数据源不能更改;在不同图表类型之间切换时,需要根据不同的图表重新填写参数,不方便自助分析;
支持多种可视化图形种类和48种数据可视化流程方案;
看板的过滤功能非常弱,连最基本的日期过滤组件没有,通过单图中的过滤器组件实现,只能针对单个数据表做出过滤组件,然后应用到看板上,此功能也很不方便。看板的过滤功能非常弱,甚至没有最基本的日期过滤组件,只能通过单图中的过滤器组件来替代,只能通过针对单个数据表制作过滤组件应用到看板上,极不方便;
支持简单的图表钻取探索功能(直接进入单图),不支持图表的联动;
数据格式(如3721,显示0.4k)方案多样化;
看板不能直接复制粘贴,只能通过重新编辑选择单图来复制粘贴看板;
看板支持自动刷新,最少10秒刷新;
支持分享:包括公开链接,网页嵌入,底层参数调整免密;
应用于chart的sql视图必须是select from的形式,否则会查询错误(不能用with as)
报表数据不支持邮件发送
不支持对图表/看板的分组
不支持图表的下钻,多图联动
不支持直接对日期范围做筛选
透视表不能按行/列做百分比汇总;
Druid引擎的计算结果,不能在superset里面生成新的指标
3)SQL查询
支持关联填补字段/表信息
支持跨库关联查询
一个多选项卡环境,一次处理多个查询
查询结果可视化,保存视图跳转到chart页面;且需要对该视图做赋权(过程过于繁琐)
可搜索查询历史记录;
支持使用Jinja模板语言模板化,允许在SQL代码中使用宏
4)权限管理
通过设置角色权限,用户指定角色来控制权限
权限控制的粒度精细,支持功能型的权限控制(表的修改可细分到删除和添加),支持菜单,数据源,数据表,字段,图表,看板的权限控制
配置权限繁琐
不支持数据行级控制
5) 二次开发
技术架构:Python+Flask+Recat+Redux+SQLAlchemy
原属Airbnb的开源项目,维护更新,bug修复和二次开发有大公司保障
支持restful API
2、Metabase (开源,gihub star 15,670)
官方宣传特色
5分钟设置仪表板
使用者无需学习SQL
丰富美观的仪表板,支持自动刷新和全屏
适合分析师和数据专业人员的SQL模式
定向邮件发送数据
目前来说,个人体验下来,感觉有这些:
安装教程很繁琐,和装MySQL一样麻烦
仅支持单表获取,不支持表连接,计算速度取决于数据库的速度
有许多可视化选项,并且有多套基于经纬度的地理位置可视化方案
权限控制很细,下至每个功能键
遗憾的是,最大的问题是业务分析师的用户体验不是很好,数据可视化流程是为不同图形方案设置相应的参数,权限控制复杂。
各方面的具体情况如下:
1)数据源与数据管理
支持多种数据库:Athena、Redshift、Drill、Druid、Hive、Impala、Kylin、Spark SQL、BigQuery、Pinot、ClickHouse、Google Sheets、Greenplum、IBM Db2、MySQL、Oracle、PostgreSQL、Presto、Snowflake、SQLite、SQL Server、Teradata、Vertica、支持上传本地CSV文件
对于数据表模型的管理,可以设置字段类型、维度/是否过滤/是否制作时间列、二次处理字段、统计指标
图表可用的数据表必须从数据库中逐个添加(可以在SQL工具箱中看到它们),这不是很方便
深度支持durid
2)chart单图&dashboard看板
单图制作流程:选择数据源(表或视图)->选择图表类型->设置图表参数(指标/维度/过滤条件)。只能从数据表列表页选择数据源。进入分析页面后,数据源不能更改;在不同图表类型之间切换时,需要根据不同的图表重新填写参数,不方便自助分析;
支持多种可视化图形种类和48种数据可视化流程方案;
看板的过滤功能非常弱,连最基本的日期过滤组件没有,通过单图中的过滤器组件实现,只能针对单个数据表做出过滤组件,然后应用到看板上,此功能也很不方便。看板的过滤功能非常弱,甚至没有最基本的日期过滤组件,只能通过单图中的过滤器组件来替代,只能通过针对单个数据表制作过滤组件应用到看板上,极不方便;
支持简单的图表钻取探索功能(直接进入单图),不支持图表的联动;
数据格式(如3721,显示0.4k)方案多样化;
看板不能直接复制粘贴,只能通过重新编辑选择单图来复制粘贴看板;
看板支持自动刷新,最少10秒刷新;
支持分享:包括公开链接,网页嵌入,底层参数调整免密;
应用于chart的sql视图必须是select from的形式,否则会查询错误(不能用with as)
报表数据不支持邮件发送
不支持对图表/看板的分组
不支持图表的下钻,多图联动
不支持直接对日期范围做筛选
透视表不能按行/列做百分比汇总;
Druid引擎的计算结果,不能在superset里面生成新的指标
3)SQL查询
支持关联填补字段/表信息
支持跨库关联查询
一个多选项卡环境,一次处理多个查询
查询结果可视化,保存视图跳转到chart页面;且需要对该视图做赋权(过程过于繁琐)
可搜索查询历史记录;
支持使用Jinja模板语言模板化,允许在SQL代码中使用宏
4)权限管理
通过设置角色权限,用户指定角色来控制权限
权限控制的粒度精细,支持功能型的权限控制(表的修改可细分到删除和添加),支持菜单,数据源,数据表,字段,图表,看板的权限控制
配置权限繁琐
不支持数据行级控制
5) 二次开发
技术架构:Python+Flask+Recat+Redux+SQLAlchemy
原属Airbnb的开源项目,维护更新,bug修复和二次开发有大公司保障
支持restful API
2、Metabase (开源,gihub star 15,670)
官方宣传特色
5分钟设置仪表板
使用者无需学习SQL
丰富美观的仪表板,支持自动刷新和全屏
适合分析师和数据专业人员的SQL模式
定向邮件发送数据
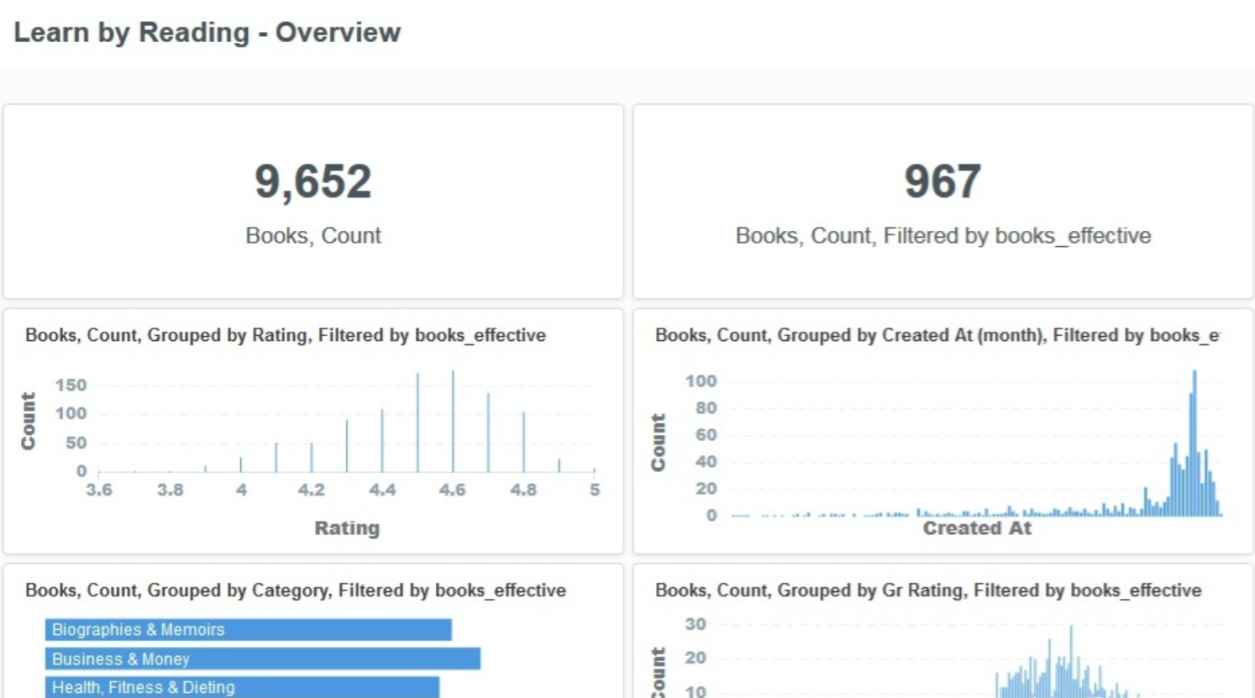 对于这个,体验感受如下:
交互体验对业务人员非常友好。通过看板和单图的全局搜索功能,营造”ask a question“的智能场景,即通过搜索框咨询答案,整个产品的界面非常简洁清晰。
制作单图时非常简单,以数据为中心选择不同的图形(非可选图形自动显灰)。可以做到单图分析半分钟完成。
然而,最大的缺点是权限管理太弱。只有可修改/可见的粗粒度控制,对于是否可以删除表没有单独的控制。
各方面的具体情况如下:
1)数据源与数据管理
支持的数据库相对较弱:Postgres、MySQL、SQL Server、Redshift、SQLite、Google BigQuery、H2、Oracle、Vertica、Snowflake、MongoDB、Druid、Presto、SparkSQL
(特别需要注意的是:其中Druid的版本为2.0版本,不支持sql查询,效果大打折扣;另外也不支持Hive,Kylin)
统一的数据模型管理入口,添加数据表/视图后,设置维度/度量字段(这部分很细节,大大扩展了设定的类型)
提供定时任务,数据库同步(以时为单位)
自助的表字段信息透视功能,智能化探索,自动显示看板,自动关联数据分布(特别有用)
对于这个,体验感受如下:
交互体验对业务人员非常友好。通过看板和单图的全局搜索功能,营造”ask a question“的智能场景,即通过搜索框咨询答案,整个产品的界面非常简洁清晰。
制作单图时非常简单,以数据为中心选择不同的图形(非可选图形自动显灰)。可以做到单图分析半分钟完成。
然而,最大的缺点是权限管理太弱。只有可修改/可见的粗粒度控制,对于是否可以删除表没有单独的控制。
各方面的具体情况如下:
1)数据源与数据管理
支持的数据库相对较弱:Postgres、MySQL、SQL Server、Redshift、SQLite、Google BigQuery、H2、Oracle、Vertica、Snowflake、MongoDB、Druid、Presto、SparkSQL
(特别需要注意的是:其中Druid的版本为2.0版本,不支持sql查询,效果大打折扣;另外也不支持Hive,Kylin)
统一的数据模型管理入口,添加数据表/视图后,设置维度/度量字段(这部分很细节,大大扩展了设定的类型)
提供定时任务,数据库同步(以时为单位)
自助的表字段信息透视功能,智能化探索,自动显示看板,自动关联数据分布(特别有用)
 2)chart单图&dashboard看板
单图制作流程简单:选择数据源->选择过滤条件->选择分析指标->选择分组维度->选择可视化类型
支持的可视化图形种类单一,14种数据可视化流程方案(包含漏斗、带变化的数字、地图)仅能满足基本需求,
可以对图表进行细节控制,比如表单根据条件控制行颜色,调整字段位置,显示迷你颜色栏,设置前后缀
支持基本过滤条件,包括日期段(筛选器的字段与单图中字段之间的关联)
提供简单的图表钻取功能,但不支持图表的联动
现有看板一键复制
自动刷新数据,最小粒度1分钟
支持分享:公开链接,公开嵌入(博客网页),嵌入应用
使用Pulses发送数据给Slack(一个国外的聊天工具)或发送电子邮件
3)SQL查询
支持关联填补字段/表信息
sql查询结果直接转换为图形展示方案
不支持跨库关联查询
原生查询中的变量允许使用筛选组件或URL参数来动态替换查询值
SELECT count(*)
FROM products
WHERE 1=1
[[AND id = {{id}}]]
[[AND category = {{category}}]]
4)权限管理
设置角色权限,用户指定角色,控制角色权限
权限设置粗糙,仅设置可访问权限(可直接删除可访问的数据)
权限设置对象不深:权限控制范围只有数据源,数据表,图表,分析项目集合,不涉及数据行级
字段级的字段控制可设置不可见(敏感字段),但不能角色权限管理区别
5)二次开发
技术架构:Clojure+Recat+Redux
提供了完整的API文档,可凭借丰富的API与文档完成多种二次开发
3、FineBI(商业)
官方的宣传特色:
零代码5分钟完成数据分析,点击拖拽完成分析,半个小时内完成数据报表
满足各种分析需求,数据处理,探索式OLAP分析,自助式数据分析
首要是自助数据集功能,普通业务人员可以对数据进行筛选、切割、排序、汇总等,自助灵活实现所需数据结果
一键式数据共享和管控,精致的数据权限管控,数据和报表实现全公司实时共享更新
支持大量数据分析,采用先进的列式存储,高效计算能力和强大的数据压缩能力,支持前端快速数据分析
2)chart单图&dashboard看板
单图制作流程简单:选择数据源->选择过滤条件->选择分析指标->选择分组维度->选择可视化类型
支持的可视化图形种类单一,14种数据可视化流程方案(包含漏斗、带变化的数字、地图)仅能满足基本需求,
可以对图表进行细节控制,比如表单根据条件控制行颜色,调整字段位置,显示迷你颜色栏,设置前后缀
支持基本过滤条件,包括日期段(筛选器的字段与单图中字段之间的关联)
提供简单的图表钻取功能,但不支持图表的联动
现有看板一键复制
自动刷新数据,最小粒度1分钟
支持分享:公开链接,公开嵌入(博客网页),嵌入应用
使用Pulses发送数据给Slack(一个国外的聊天工具)或发送电子邮件
3)SQL查询
支持关联填补字段/表信息
sql查询结果直接转换为图形展示方案
不支持跨库关联查询
原生查询中的变量允许使用筛选组件或URL参数来动态替换查询值
SELECT count(*)
FROM products
WHERE 1=1
[[AND id = {{id}}]]
[[AND category = {{category}}]]
4)权限管理
设置角色权限,用户指定角色,控制角色权限
权限设置粗糙,仅设置可访问权限(可直接删除可访问的数据)
权限设置对象不深:权限控制范围只有数据源,数据表,图表,分析项目集合,不涉及数据行级
字段级的字段控制可设置不可见(敏感字段),但不能角色权限管理区别
5)二次开发
技术架构:Clojure+Recat+Redux
提供了完整的API文档,可凭借丰富的API与文档完成多种二次开发
3、FineBI(商业)
官方的宣传特色:
零代码5分钟完成数据分析,点击拖拽完成分析,半个小时内完成数据报表
满足各种分析需求,数据处理,探索式OLAP分析,自助式数据分析
首要是自助数据集功能,普通业务人员可以对数据进行筛选、切割、排序、汇总等,自助灵活实现所需数据结果
一键式数据共享和管控,精致的数据权限管控,数据和报表实现全公司实时共享更新
支持大量数据分析,采用先进的列式存储,高效计算能力和强大的数据压缩能力,支持前端快速数据分析
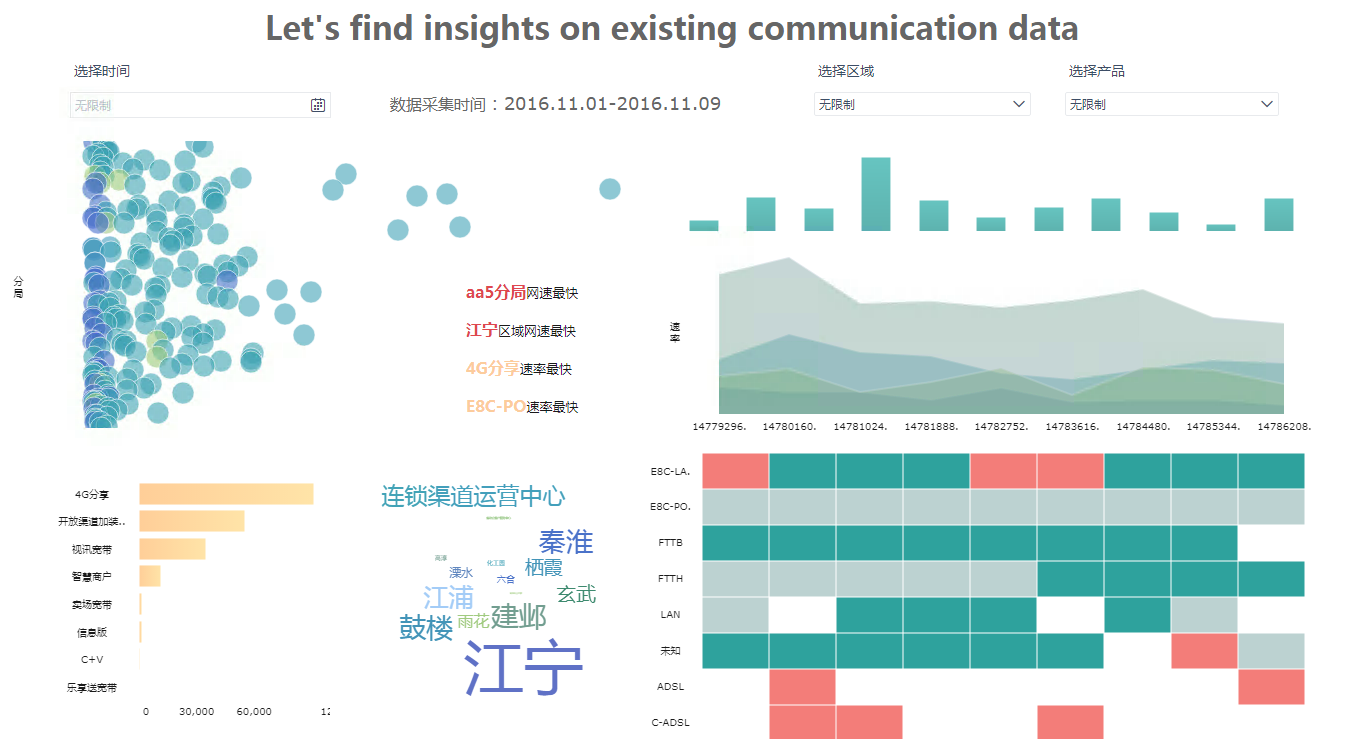 总的来说,亲身体验感受如下:
新手使用需要适应流程,配置数据,处理自助数据集,制作可视化仪表板和图表,有点记不住
数据可视化流程简单,交互类似Tableau,拖拽数据字段到维度框,立即呈现可视化,然后基于可视化组件构建仪表板
联动钻取功能大,智能化,可自动关联到共性字段
数据处理功能强大,自助数据集具有多种数据处理功能,包括分组汇总、修改数据字段、合并表等
最大的亮点是权限控制细致实用,可以细分到原始数据源、已处理数据集、仪表板,可以管理不同角色用户,包括职位、部门等,有对管理员和用户的权限管控,类似OA,是这几个产品里最突出的
各方面的具体情况如下:
1)数据源与数据管理
支持的数据库多样化
业务包功能能够分类不同数据源,比如按部门或者按业务需求
可对数据表进行可视化管理、数据预览、血缘分析、关联视图等
2)chart单图&dashboard看板
数据可视化流程:连接数据源(导入数据库或excel)——自助数据集处理数据——依据数据制作图表组件——制作可视化仪表板。
可视化图表多样,有50多种基本图表,然后加上图表间的重叠使用样式设置能达到100多种;
有分组、交叉、明细等表格类型,不支持复杂的表格,复杂表格可以用报表软件finereport
仪表板有时间、文本、数值、查询等过滤组件,过滤功能有自定义条件过滤;
可钻取、联动、跳转数据,实现仪表板内互动,以及仪表板之间互动,支持图表的联动;
可以反复使用组件、看板,直接复制即可
有丰富的函数功能,在数据可视化流程中对数据进行二次的过滤、汇总、排序、以及自定义公式计算
仪表板定时刷新,可定时自动刷新单个仪表板、多个仪表板板和单个组件,但需要JS写定时刷新频率
支持仪表板公开链接,决策系统,网页嵌入等共享方式
仪表板直接共享、创建公共链接、悬挂仪表板。
总的来说,亲身体验感受如下:
新手使用需要适应流程,配置数据,处理自助数据集,制作可视化仪表板和图表,有点记不住
数据可视化流程简单,交互类似Tableau,拖拽数据字段到维度框,立即呈现可视化,然后基于可视化组件构建仪表板
联动钻取功能大,智能化,可自动关联到共性字段
数据处理功能强大,自助数据集具有多种数据处理功能,包括分组汇总、修改数据字段、合并表等
最大的亮点是权限控制细致实用,可以细分到原始数据源、已处理数据集、仪表板,可以管理不同角色用户,包括职位、部门等,有对管理员和用户的权限管控,类似OA,是这几个产品里最突出的
各方面的具体情况如下:
1)数据源与数据管理
支持的数据库多样化
业务包功能能够分类不同数据源,比如按部门或者按业务需求
可对数据表进行可视化管理、数据预览、血缘分析、关联视图等
2)chart单图&dashboard看板
数据可视化流程:连接数据源(导入数据库或excel)——自助数据集处理数据——依据数据制作图表组件——制作可视化仪表板。
可视化图表多样,有50多种基本图表,然后加上图表间的重叠使用样式设置能达到100多种;
有分组、交叉、明细等表格类型,不支持复杂的表格,复杂表格可以用报表软件finereport
仪表板有时间、文本、数值、查询等过滤组件,过滤功能有自定义条件过滤;
可钻取、联动、跳转数据,实现仪表板内互动,以及仪表板之间互动,支持图表的联动;
可以反复使用组件、看板,直接复制即可
有丰富的函数功能,在数据可视化流程中对数据进行二次的过滤、汇总、排序、以及自定义公式计算
仪表板定时刷新,可定时自动刷新单个仪表板、多个仪表板板和单个组件,但需要JS写定时刷新频率
支持仪表板公开链接,决策系统,网页嵌入等共享方式
仪表板直接共享、创建公共链接、悬挂仪表板。
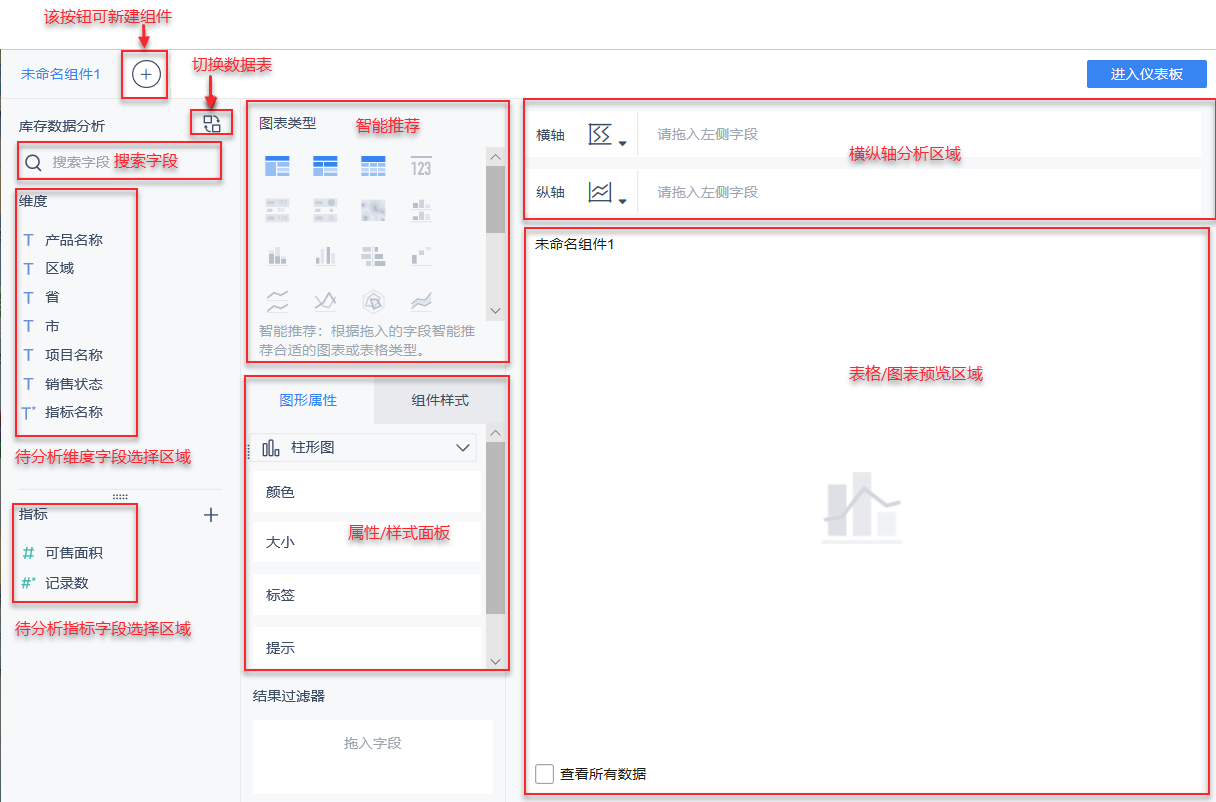 3)SQL查询
JDBC直连数据库
支持跨库关联查询
支持SQL数据集,允许SQL取数
支持可视化数据预览,在添加更新数据表后,业务包编辑界面会有数据预览区域,可以查看编辑成功的表数据。
可视化关联表和血缘分析
BI工程提供实时数据和抽取数据两种计算模式
4)权限管理
可通过角色设置权限,权限受体包括部门、角色、职务和用户
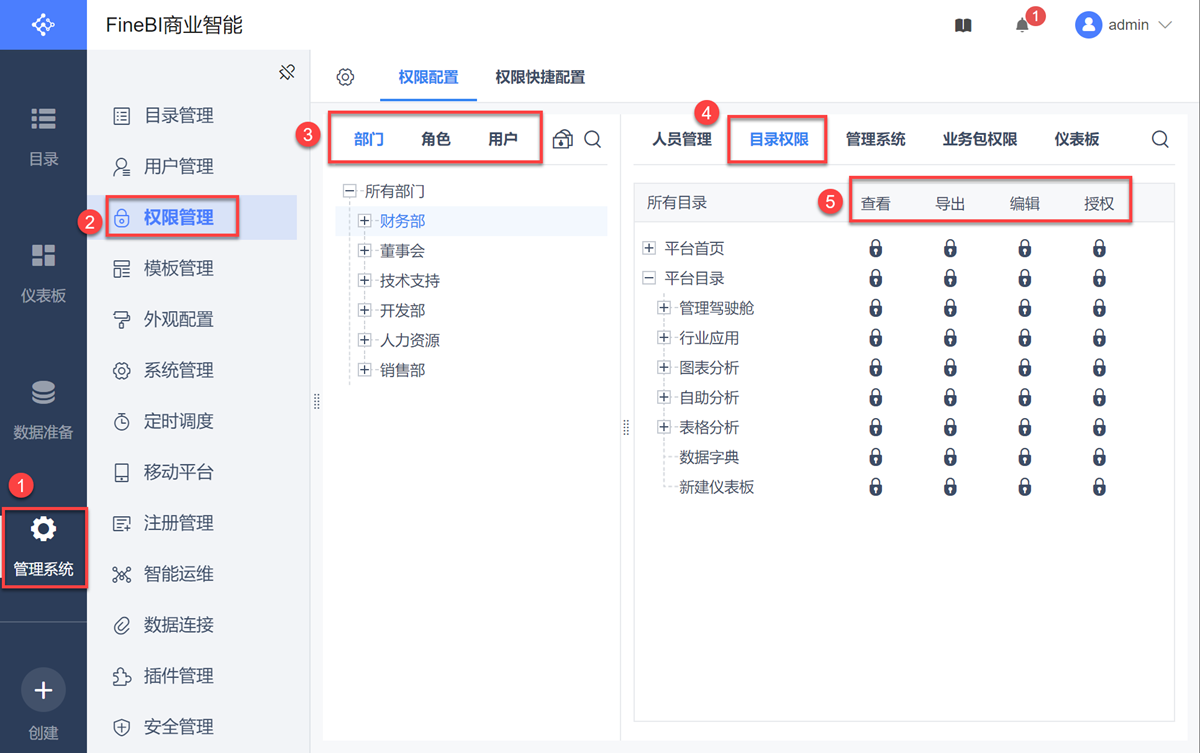
权限可设置人员管理、目录权限、管理系统、数据连接、数据权限(数据表)、分享权限、定时调度管理权限等,权限设置粒度多
权限设置对象深,可细致到组件乃至数据行级
3)SQL查询
JDBC直连数据库
支持跨库关联查询
支持SQL数据集,允许SQL取数
支持可视化数据预览,在添加更新数据表后,业务包编辑界面会有数据预览区域,可以查看编辑成功的表数据。
可视化关联表和血缘分析
BI工程提供实时数据和抽取数据两种计算模式
4)权限管理
可通过角色设置权限,权限受体包括部门、角色、职务和用户
权限可设置人员管理、目录权限、管理系统、数据连接、数据权限(数据表)、分享权限、定时调度管理权限等,权限设置粒度多
权限设置对象深,可细致到组件乃至数据行级
 5) 二次开发
纯java开发,可以零代码操作
支持一定的二次开发,有API文档
5) 二次开发
纯java开发,可以零代码操作
支持一定的二次开发,有API文档


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号



