 全部案例
全部案例
 离线数据可以使用Sqoop抽取关系型数据库到HDFS。
离线数据可以使用Sqoop抽取关系型数据库到HDFS。

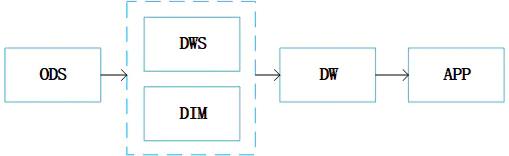 这是一个简单的数据分层结构。原始数据ODS,经过清洗成为数仓中的明细数据DWS和维度数据DIM,各个业务的明细数据按照业务域和维度数据关联形成我们的数据模型DW,不同的DW经过聚合形成各个业务指标数据APP层。
这是一个简单的数据分层结构。原始数据ODS,经过清洗成为数仓中的明细数据DWS和维度数据DIM,各个业务的明细数据按照业务域和维度数据关联形成我们的数据模型DW,不同的DW经过聚合形成各个业务指标数据APP层。
 在数仓的建设中我们声明业务粒度,粒度能够精确的表明业务含义。同时还要确定维度,是用户维度还是商品维度等,最终形成我们的主数据,也就是模型数据的基础。
在数仓的建设中我们声明业务粒度,粒度能够精确的表明业务含义。同时还要确定维度,是用户维度还是商品维度等,最终形成我们的主数据,也就是模型数据的基础。

 与业务研发不同,数据研发一般很少写详细的需求涉及文档,通常就是和业务人员简单的沟通,但是慢慢的你会发现开发完的任务会一改再改。为了避免此种现象,我们可以根据自己的实际业务整理一份需求模板。其中包括数据来源字段,数据口径,任务调度周期,字段mapping。
与业务研发不同,数据研发一般很少写详细的需求涉及文档,通常就是和业务人员简单的沟通,但是慢慢的你会发现开发完的任务会一改再改。为了避免此种现象,我们可以根据自己的实际业务整理一份需求模板。其中包括数据来源字段,数据口径,任务调度周期,字段mapping。
 数据服务标准:数据结构标准化、在线查询实时化、数据开发可视化。
数据结构标准化
针对数据交互,我们需要提供统一的接口视图,可进行数据的查询、权限管控。
在线查询实时化
针对各业务的调用,我们需要提供指标级数据口径统一的实时数据结果。
数据开发可视化
提供数据接口的可视化统一管理页面,开发人员通过通过可视化管理API,降低接口理解的难度,易于维护。
数据服务标准:数据结构标准化、在线查询实时化、数据开发可视化。
数据结构标准化
针对数据交互,我们需要提供统一的接口视图,可进行数据的查询、权限管控。
在线查询实时化
针对各业务的调用,我们需要提供指标级数据口径统一的实时数据结果。
数据开发可视化
提供数据接口的可视化统一管理页面,开发人员通过通过可视化管理API,降低接口理解的难度,易于维护。
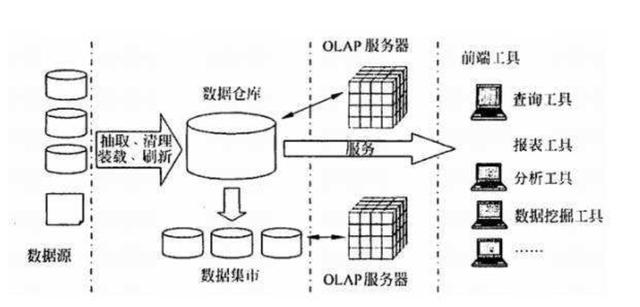
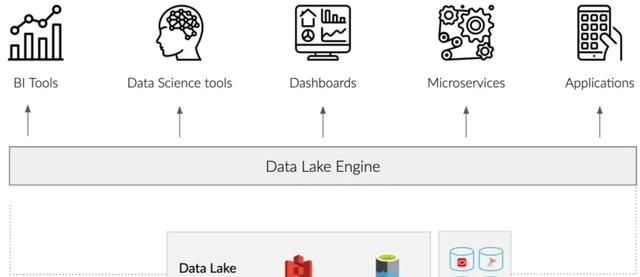 数百万数据消费者使用的工具,如BI工具、数据科学平台和仪表板工具,假设所有数据都存在于一个高性能的关系数据库中,当数据在多个系统中,或者在非关系存储(如ADLS、Amazon S3、Hadoop和NoSQL数据库)中,这些工具的能力就会受到影响。
BI分析工具,如FineBI/Tableau/Python和机器学习模型,是为数据生活在一个单一的、高性能的关系数据库中的环境而设计的。
然而,多数组织使用不同的数据格式和不同的技术在多种解决方案中管理他们的数据。多数组织现在使用一个或多个非关系型数据存储,如云存储(如S3、ADLS)、Hadoop和NoSQL数据库(如Elasticsearch、Cassandra)。
当数据存储在一个独立的高性能关系数据库中时,BI工具、数据科学系统和机器学习模型可以很好运用这部分数据。然而,就像我们上面所说的一样,数据这并不是存在一个地方。
因此,它的任务是将这些数据转移到关系环境中,创建多维数据集,并为不同的分析工具生成专用视图。数据湖引擎简化了这些挑战,允许公司将数据存放在任何地方。
数百万数据消费者使用的工具,如BI工具、数据科学平台和仪表板工具,假设所有数据都存在于一个高性能的关系数据库中,当数据在多个系统中,或者在非关系存储(如ADLS、Amazon S3、Hadoop和NoSQL数据库)中,这些工具的能力就会受到影响。
BI分析工具,如FineBI/Tableau/Python和机器学习模型,是为数据生活在一个单一的、高性能的关系数据库中的环境而设计的。
然而,多数组织使用不同的数据格式和不同的技术在多种解决方案中管理他们的数据。多数组织现在使用一个或多个非关系型数据存储,如云存储(如S3、ADLS)、Hadoop和NoSQL数据库(如Elasticsearch、Cassandra)。
当数据存储在一个独立的高性能关系数据库中时,BI工具、数据科学系统和机器学习模型可以很好运用这部分数据。然而,就像我们上面所说的一样,数据这并不是存在一个地方。
因此,它的任务是将这些数据转移到关系环境中,创建多维数据集,并为不同的分析工具生成专用视图。数据湖引擎简化了这些挑战,允许公司将数据存放在任何地方。


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号



