 全部案例
全部案例
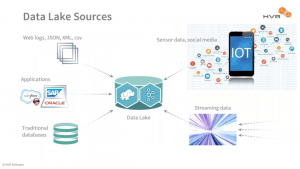 数据湖通常采用Hadoop作为数据的承载对象,随着企业规模的扩大,不同类型的数据越来越多,最终所有企业或个人相关的数据,都被认为是“大数据”,虽然廉价的HDFS是存储数据的最佳选择,但面对更多种类更多时效性要求的数据,使得Hadoop体系无法成为所有场景的最佳答案。
数据湖通常采用Hadoop作为数据的承载对象,随着企业规模的扩大,不同类型的数据越来越多,最终所有企业或个人相关的数据,都被认为是“大数据”,虽然廉价的HDFS是存储数据的最佳选择,但面对更多种类更多时效性要求的数据,使得Hadoop体系无法成为所有场景的最佳答案。
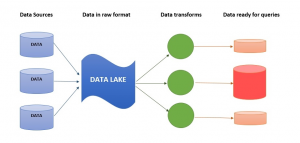
 额外提一下,数据仓库非常倾向于事前定义,也就是从事务系统中提取,经过维度或其他方式建模后,固化下来。这么做虽然能够更加清晰地展示基础数据结构,降低数据计算量,提升开发速度,但同时也带来了基础模型改动成本高、数据迁移周期长、数据质量管控难等问题,可以说高度结构化的数据仓库,更适合于月度报告等操作用途。
而数据湖倾向于所有数据都保持原始形式,在使用的时候直接用工具来统计分析,对于数据科学家而言,使用起来更加灵活,但同时也非常考验数据引擎的性能,以及科学家对于数据的掌握程度。
额外提一下,数据仓库非常倾向于事前定义,也就是从事务系统中提取,经过维度或其他方式建模后,固化下来。这么做虽然能够更加清晰地展示基础数据结构,降低数据计算量,提升开发速度,但同时也带来了基础模型改动成本高、数据迁移周期长、数据质量管控难等问题,可以说高度结构化的数据仓库,更适合于月度报告等操作用途。
而数据湖倾向于所有数据都保持原始形式,在使用的时候直接用工具来统计分析,对于数据科学家而言,使用起来更加灵活,但同时也非常考验数据引擎的性能,以及科学家对于数据的掌握程度。


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号



