 全部案例
全部案例
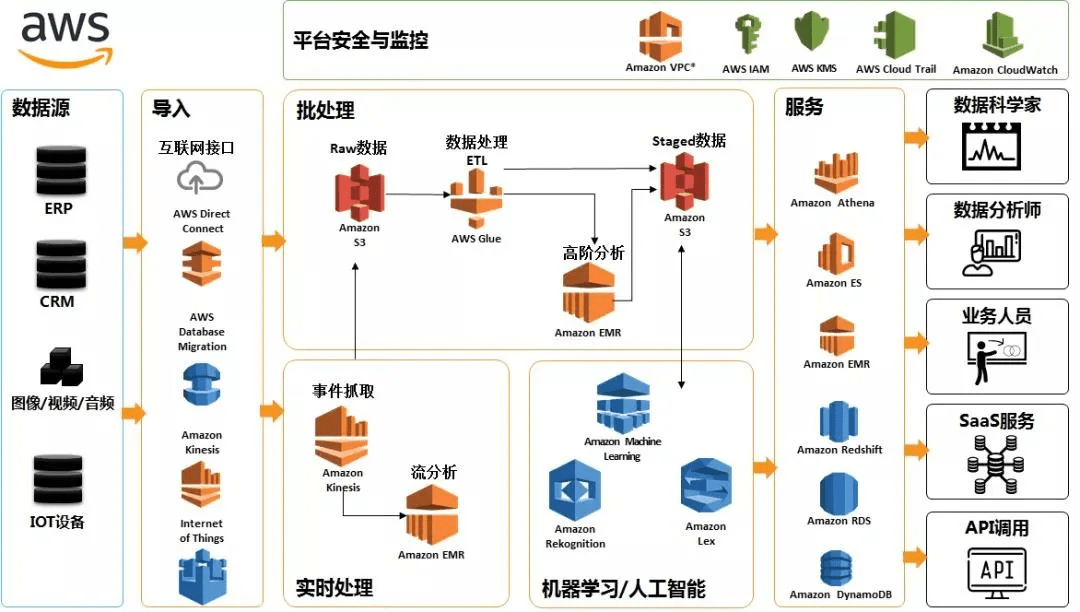 不懂数据的人也许会觉得数据湖很厉害,而懂数据的人也许会觉得仅是一堆数据仓库技术的堆砌包装而已,你看上面那张框架图,哪个专业词汇数据人士会不懂?凭什么数据湖被炒作成了一个新概念?
有比较才有鉴别,因此很多文章对数据湖与数据仓库做了比较,下面是网上流传的一些说法:
不懂数据的人也许会觉得数据湖很厉害,而懂数据的人也许会觉得仅是一堆数据仓库技术的堆砌包装而已,你看上面那张框架图,哪个专业词汇数据人士会不懂?凭什么数据湖被炒作成了一个新概念?
有比较才有鉴别,因此很多文章对数据湖与数据仓库做了比较,下面是网上流传的一些说法:
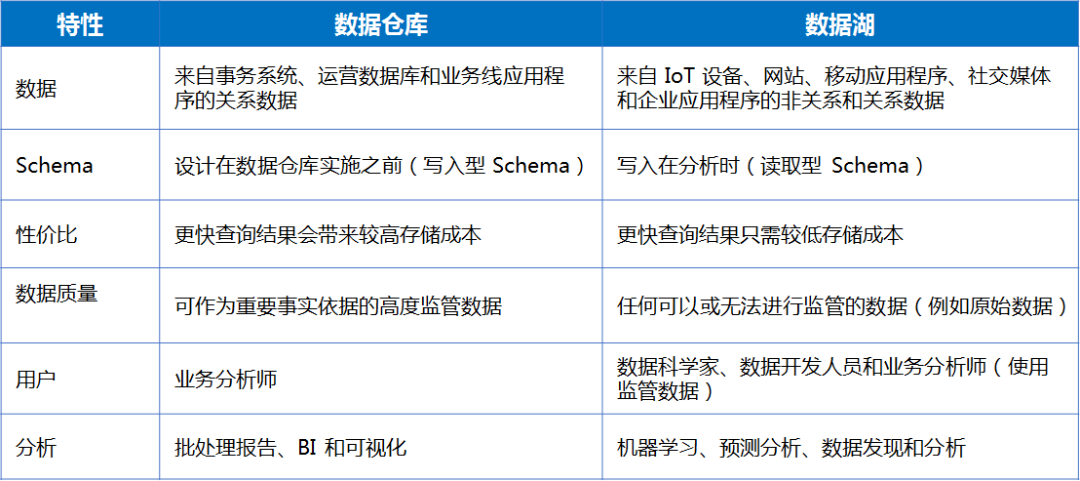 这种比较似乎能找到点区别,难道结构化与非结构化就成了数据仓库和数据湖的一个主要区别?BI和机器学习成为了主要区别?
事实上,这种比较有较大逻辑漏洞:即是从结果出发来看差异,然后又用这个差异来说明区别,颠倒了因果,因此受到了不少专业人士的鄙视。比如AWS的数据湖能够处理非结构化数据,而数据仓库无法处理非结构化数据,就认为这是数据湖与数据仓库的本质区别之一。
本文来跟大家聊聊我所理解的数据湖的本质,对于一种新事物不了解本质,你就很难驾驭它,下面这张图道尽了一切。
这种比较似乎能找到点区别,难道结构化与非结构化就成了数据仓库和数据湖的一个主要区别?BI和机器学习成为了主要区别?
事实上,这种比较有较大逻辑漏洞:即是从结果出发来看差异,然后又用这个差异来说明区别,颠倒了因果,因此受到了不少专业人士的鄙视。比如AWS的数据湖能够处理非结构化数据,而数据仓库无法处理非结构化数据,就认为这是数据湖与数据仓库的本质区别之一。
本文来跟大家聊聊我所理解的数据湖的本质,对于一种新事物不了解本质,你就很难驾驭它,下面这张图道尽了一切。
 下面我用一篇文章来具体说明数据湖与数据仓库的区别,更多的是给出why,知其所以然是理解事物的一个原则。
数据仓库和数据湖的处理流程可以用下图来示意,其中用红圈标出了5个对标的流程节点。
下面我用一篇文章来具体说明数据湖与数据仓库的区别,更多的是给出why,知其所以然是理解事物的一个原则。
数据仓库和数据湖的处理流程可以用下图来示意,其中用红圈标出了5个对标的流程节点。
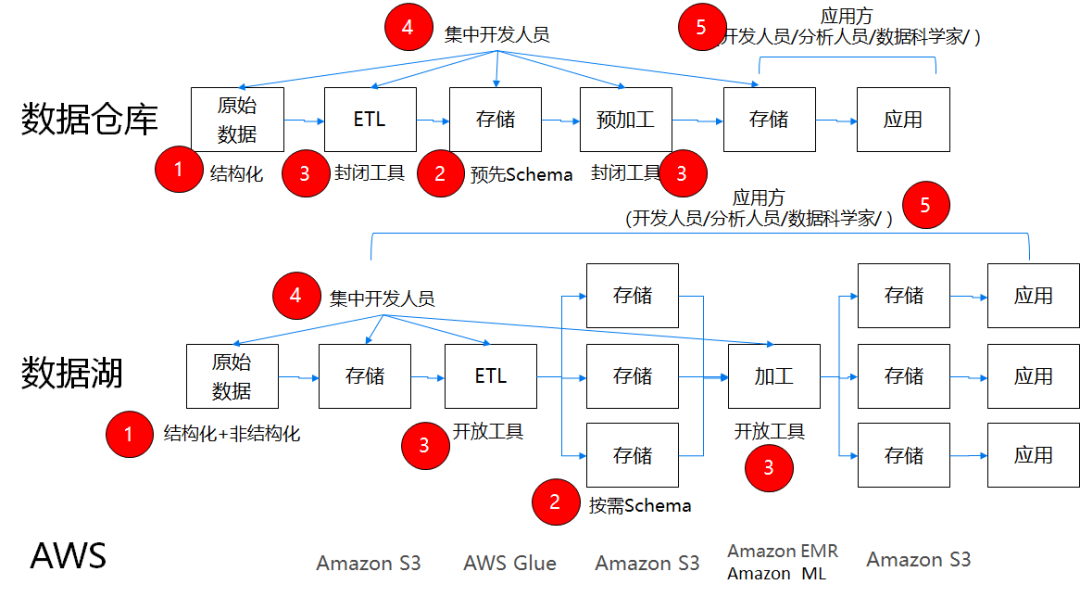 可以看到,数据湖并不比数据仓库在处理流程上多出了什么内容,更多的在于结构性的变化,下面就从数据存储、模型设计、加工工具、开发人员和消费人员五个方面来进行比较。
可以看到,数据湖并不比数据仓库在处理流程上多出了什么内容,更多的在于结构性的变化,下面就从数据存储、模型设计、加工工具、开发人员和消费人员五个方面来进行比较。
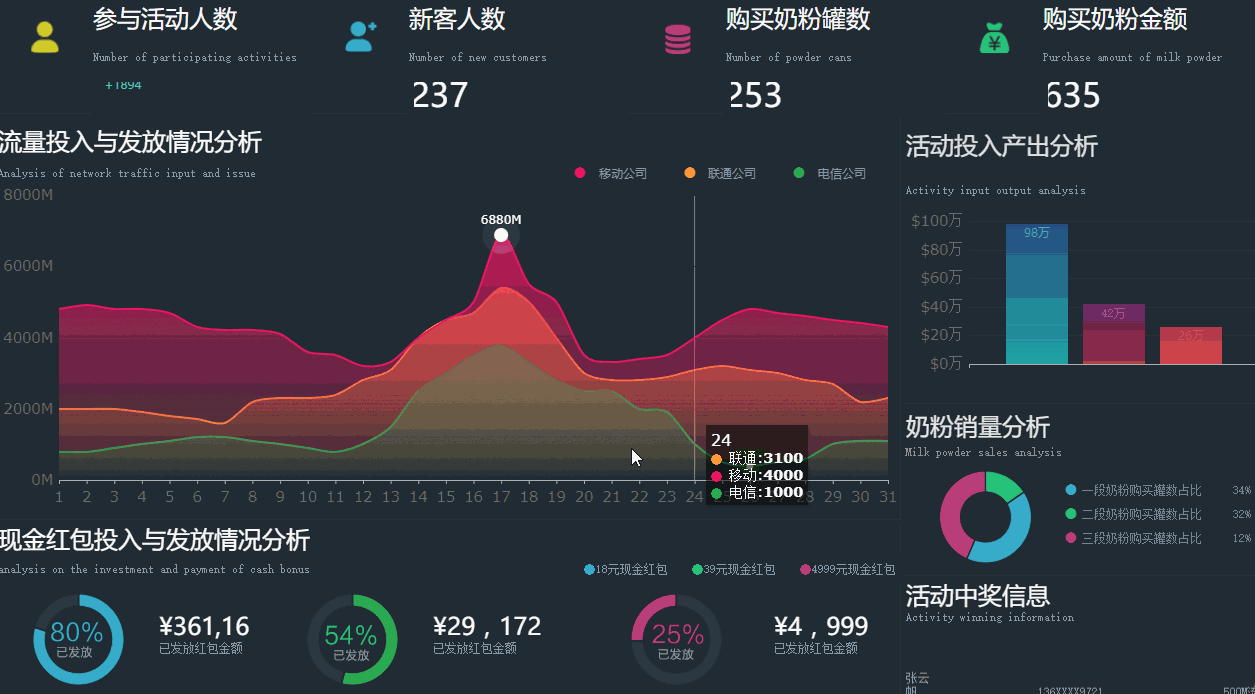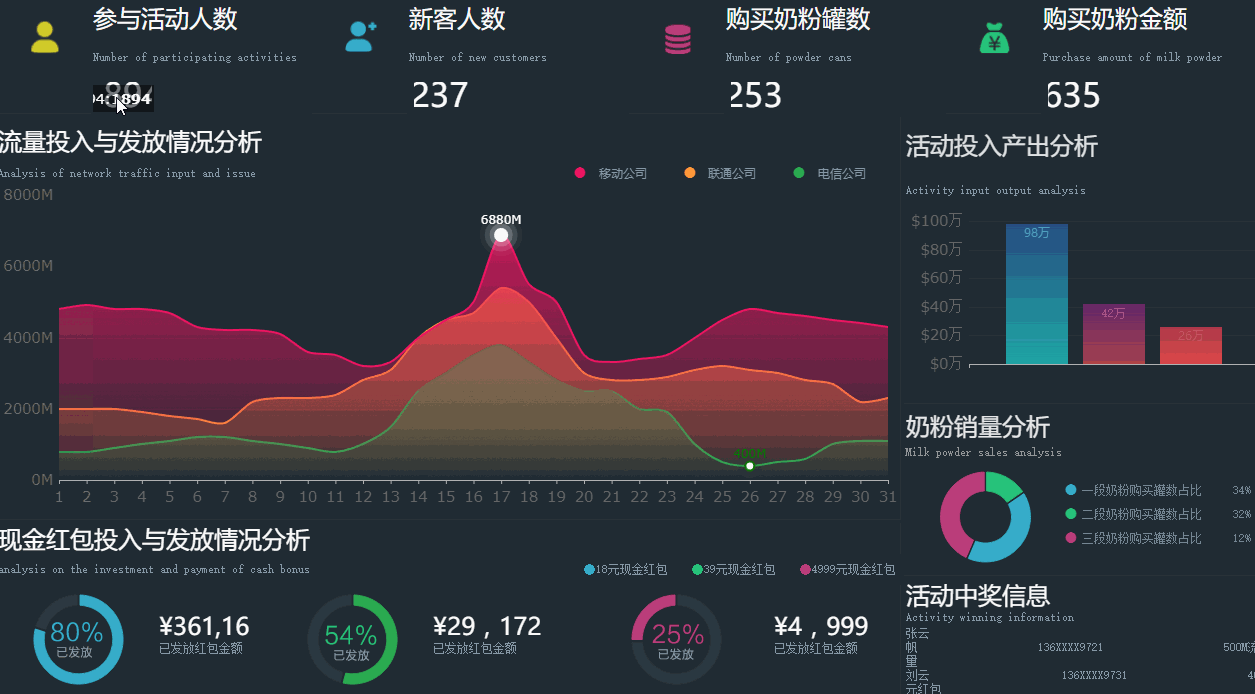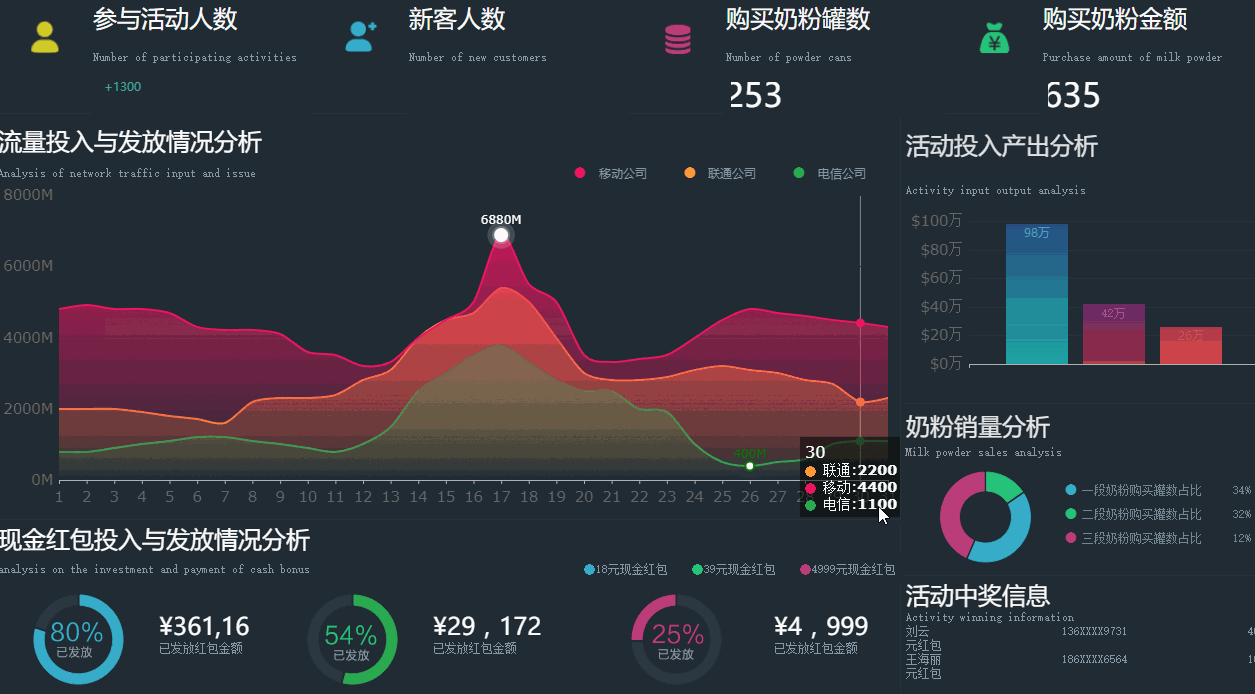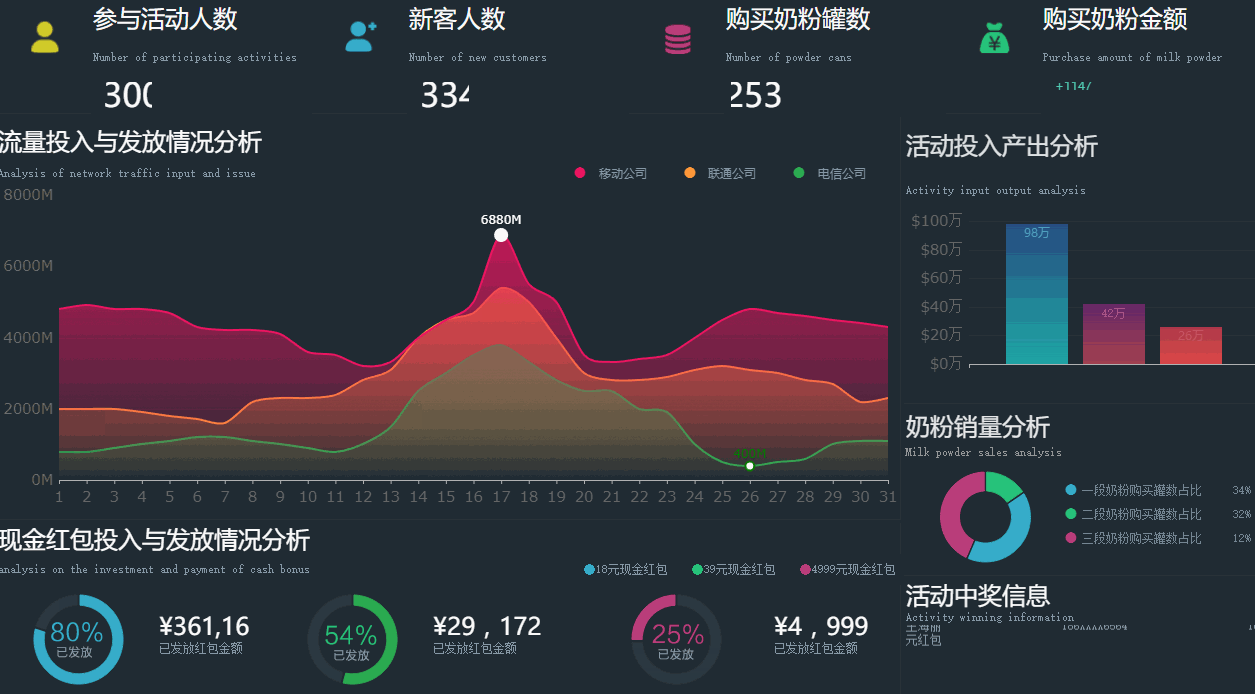 一方面企业需要深挖各种数据,从展示数据为主(报表)逐步向挖掘数据(探索预测)转变,另一方面企业也需要从按部就班的支撑模式向快速灵活的方向转变,要求数据仓库能够开放更多的灵活性给应用方,这个时候数据仓库就有点撑不住了。
数据湖就是在这种背景下诞生的。
其实早在数据湖出来之前,很多企业就在做类似数据湖的工作了,比如我们5年前重构hadoop大数据平台的时候,就已经要求源端能将各种格式的数据直接扔过来,然后用不同的引擎处理,非结构化的就自己做一个定制化的ETL工具,只是没有统一进行整合而已。
ETL之所以不开放,主要是驱动力不够,其实我们没有那么多类型的数据要定制化抽取,也许后续会需要吧。
而可视化开发平台使用比较广泛,只是因为市场觉得IT做的太慢了,需要一个可视化平台来直接操作。
很多企业不搞可视化开发平台也是容易理解的,报表就能活得很好,干嘛业务人员要自己开发和挖掘。现在数据湖叫的欢的,大多是互联网公司,比如亚马逊,这是很正常的。
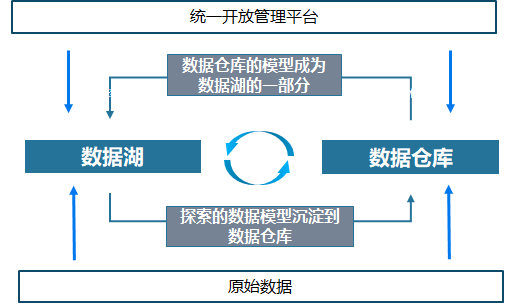
数据湖和数据仓库,不能说谁更好谁更差,大家都有可取之处,阿里最近一篇文章提到的数湖一体是很好的概念,可以实现双方的优势互补,我这里画一张图,方便你的理解:
一方面企业需要深挖各种数据,从展示数据为主(报表)逐步向挖掘数据(探索预测)转变,另一方面企业也需要从按部就班的支撑模式向快速灵活的方向转变,要求数据仓库能够开放更多的灵活性给应用方,这个时候数据仓库就有点撑不住了。
数据湖就是在这种背景下诞生的。
其实早在数据湖出来之前,很多企业就在做类似数据湖的工作了,比如我们5年前重构hadoop大数据平台的时候,就已经要求源端能将各种格式的数据直接扔过来,然后用不同的引擎处理,非结构化的就自己做一个定制化的ETL工具,只是没有统一进行整合而已。
ETL之所以不开放,主要是驱动力不够,其实我们没有那么多类型的数据要定制化抽取,也许后续会需要吧。
而可视化开发平台使用比较广泛,只是因为市场觉得IT做的太慢了,需要一个可视化平台来直接操作。
很多企业不搞可视化开发平台也是容易理解的,报表就能活得很好,干嘛业务人员要自己开发和挖掘。现在数据湖叫的欢的,大多是互联网公司,比如亚马逊,这是很正常的。
数据湖和数据仓库,不能说谁更好谁更差,大家都有可取之处,阿里最近一篇文章提到的数湖一体是很好的概念,可以实现双方的优势互补,我这里画一张图,方便你的理解:


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号



