作者:finedatalink
发布时间:2023.7.28
阅读次数:1,180 次浏览
随着大数据时代的到来,数据集成和数据管理变得越来越关键。ETL(抽取、转换和加载)是常用于将数据从一个系统移动到另一个系统的技术。然而,有时我们需要将数据从目标系统移回到源系统,这就是反向ETL。
反向ETL的主要目的是将数据从数据仓库、数据库或数据市场加载回到源系统。它可以为组织提供更精确的数据,帮助业务分析师、数据科学家等更好地工作。
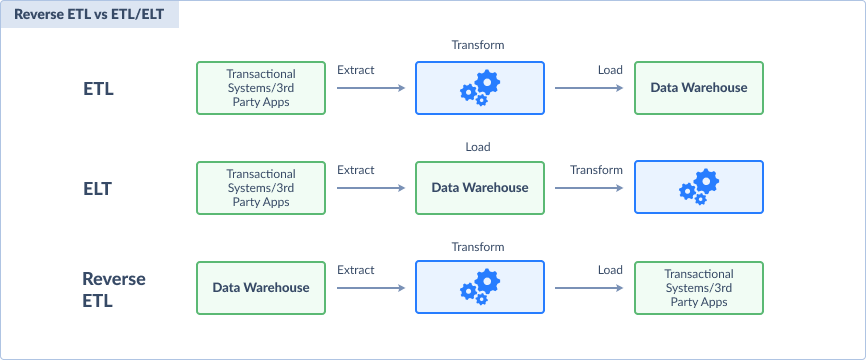
反向ETL的流程与常规的ETL过程相似,但顺序是相反的。它涉及从数据目标系统中提取数据,然后转换为源系统的格式,最后加载回源系统。因此,反向ETL也被称为ELT(抓取、加载和转换)。
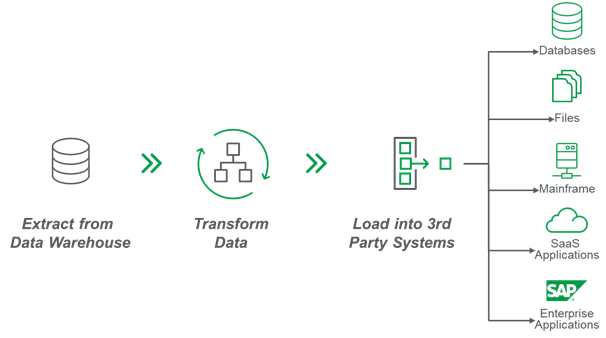
在一些情况下,我们需要将经过转换和加工的数据回流到源系统。以下是一些常见的使用反向ETL的场景:
当在目标系统中发现数据错误或不准确时,需要通过反向ETL将数据返回源系统,以便进行核实和修正。
当我们需要将数据从目标系统迁移回源系统时,反向ETL可以起到关键作用。这在系统升级、数据迁移或数据整合项目中非常常见。
通过将目标系统中的数据反向加载回源系统,可以验证数据的完整性和一致性。
反向ETL在数据集成和数据管理中发挥着重要作用。以下是它的一些关键优势:
通过将数据从目标系统迁移回源系统,并进行核实和修正,可以大大提高数据的质量和准确性。
反向ETL使组织能够跟踪数据的来源和流向,确保数据的可追溯性,这对合规性和风险管理非常重要。
反向ETL避免了手工操作,自动化了数据回流的过程,节省了人力和时间成本。
要实施反向ETL,您可以使用专门的反向ETL工具或利用常规ETL工具的功能。以下是一些实施反向ETL的步骤:
使用反向ETL工具连接目标系统并提取需要回流的数据。选择合适的数据提取策略和技术,确保数据的准确性和完整性。
将提取的数据转换为源系统的格式和结构。这包括数据清洗、格式化和映射等处理。
将经过转换的数据加载回源系统。确保数据加载过程具有幂等性和错误处理机制,以防止数据重复或丢失。
在数据加载完成后,对回流的数据进行验证和校验,确保数据的一致性和完整性。
反向ETL是一项重要的数据集成和数据管理技术,为组织提供了将数据从目标系统回流到源系统的能力。它可以改进数据质量,提供数据可追溯性,并节省成本和时间。
要实施反向ETL,您可以选择使用专门的反向ETL工具或利用常规ETL工具的功能。合理的反向ETL策略和流程设计非常重要,以确保数据的准确性和完整性。
FineDataLink是国内做的比较好的ETL工具。FineDataLink是一站式的数据处理平台,拥有低代码优势,通过简单的拖拽交互就能实现ETL全流程。具备高效的数据同步功能,可以实现实时数据传输、数据调度、数据治理等各类复杂组合场景的能力,提供数据汇聚、研发、治理等功能。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号



