作者:finedatalink
发布时间:2023.8.7
阅读次数:972 次浏览
数据清洗是数据治理过程中的一个重要环节,它指的是对原始数据进行筛选、修复、转换和处理,以确保数据的准确性、完整性和一致性。
在数据清洗过程中,不仅需要明确数据清洗的对象,还需要根据具体的情况选择合适的数据清理方法。以下是不同对象所对应不同的数据清洗方法。
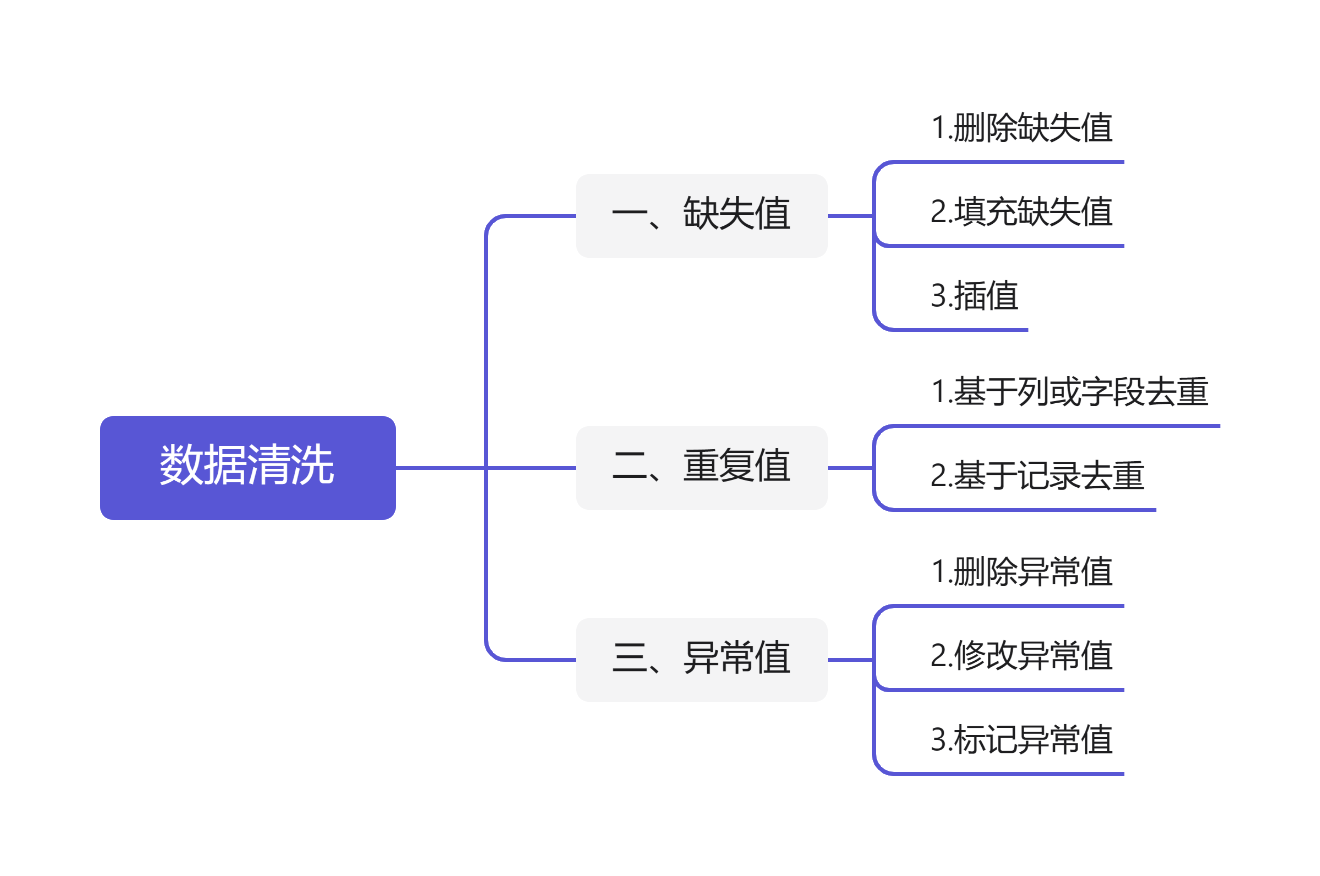
缺失值是指数据表中缺少某些观测值或数据值的情况。在处理缺失值时,可以选择删除,填充,插值等方式。
如果缺失的数据过多,影响分析的精度,可以选择删除缺失值。删除缺失值可以使用dropna()函数,该函数可以在数据集中删除缺失值较多的行或列。但是,在删除数据之前,需要对数据缺失的情况进行统计和分析,确定删除的数据的比例以及对最终分析结果的影响程度。
在处理缺失值时,也可以选择填充缺失值。填充可以使用均值、中位数、众数等方法进行,填充时需要选择与数据类型匹配的方法,并根据数据集的特点进行选取。填充缺失值的基本方法是使用fillna()函数,该函数可以根据要替换的规则对数据集进行填充。
在缺失值较多的情况下,可以使用插值方法根据数据集的曲线趋势预测缺失值。插值方法可以分为线性插值,多项式插值以及样条插值等。
处理缺失值时需要根据实际情况判断采取何种方法,需要根据不同的数据集特征和分析目的进行分析。对于缺失值,建议在进行数据清理之前,先确定缺失值的特征,收集清洗规则,并根据规则进行清洗。避免对数据的清洗产生不必要的干扰。
重复值是指数据表中存在重复的记录或数据,重复值的存在会对数据分析产生混淆和误导,因此需要进行去重。
对数据表按照某个或多个字段进行排序,将相同的字段数据区分为同一类别,将相同类别的记录视为重复数据,进行删除或保留操作。
按照行索引(row index)或者行号来去重,将相同行索引或行号的记录保留一份,然后删除其余记录。
对于重复值,需要根据实际情况选择不同的处理方法,最终确保数据的准确性和一致性。在去重处理之前,重要的是要根据数据集中的特点来进行分析,确定重复值的数量和匹配规则。如果数据量非常大,可以使用ETL工具进行批处理,以提高数据处理的效率。
异常值是指数据表中存在明显异常或离群的数据。在数据分析中,异常值会对数据进行较大的干扰,影响分析结果的精度和准确性。在处理异常值时,可以选择删除、修改或标注等方法。
如果异常值只是个别存在,可以考虑将其删除。删除异常值可以使用drop()函数,该函数可以定位到特定位置的异常值,并从数据集中删除。
将异常值替换为可接受的值,例如将异常值替换为平均值、中位数等,或者根据数据集的放大缩小比例,将数据范围缩小到合理的范围内(例如数据集比例放大100倍后进行删减或缩小)。
在处理过程中对异常值进行标记,例如标记-999、缩写AB等,这些标记可较精确说明异常情况,用在分析数据时,就可以减少这些异常值的影响。
在处理异常值时,需要谨慎对待,避免误删或误修改正常数据。一般来说,处理方法应该基于数据分布的统计分析,结合数据的实际内容和业务需求,去除或合理处理异常值,从而能够保证数据分析结果的准确性和可靠性。
FineDataLink是一款低代码/高时效的数据集成平台,它不仅提供了数据清理和数据分析的功能,还能够将清理后的数据快速应用到其他应用程序中。FineDataLink的功能非常强大,可以轻松地连接多种数据源,包括数据库、文件、云存储等。此外,FineDataLink还支持高级数据处理功能,例如数据转换、数据过滤、数据重构、数据集合等。使用FineDataLink可以显著提高团队协作效率,减少数据连接和输出的繁琐步骤,使整个数据处理流程更加高效和便捷。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: FDL提高业务效率:数据驱动的决策质量跃升下一篇: 数据清洗技巧:打造可信赖的数据集成系统


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号



