作者:finedatalink
发布时间:2023.7.31
阅读次数:1,093 次浏览
在当今数据爆炸的时代,企业在业务运营和决策制定中需要处理海量的数据。而数据仓库模型的设计就是为了提供一个高效、可靠的数据管理体系,帮助企业在复杂的数据环境中进行数据整合、存储和分析。本文将介绍如何设计一个高效的数据仓库模型,从而构建一个可靠、可扩展的数据管理体系,提高数据处理和分析的效率。
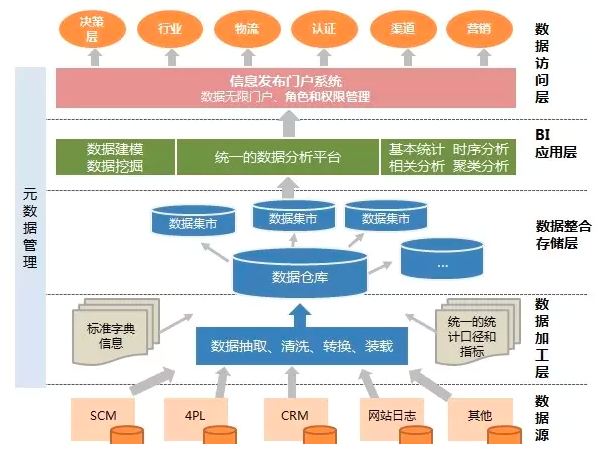
在设计过程中,需要与业务人员密切合作,深入了解业务逻辑和数据关系。同时,对于数据的来源、格式、粒度和变化情况也需要进行全面的调研和分析。只有充分了解业务需求和数据特点,才能设计出符合实际需求的数据仓库模型。
在建模过程中,可以采用维度建模或者实体关系建模等方法。
维度建模常用于OLAP场景,以事实表和维度表为核心,通过星型或者雪花模型构建数据仓库模型。
实体关系建模则适用于OLTP场景,通过实体和关系构建数据模型。选择合适的建模方法和技术,能够有效地提高数据仓库的查询性能和数据处理效率。
数据的存储方式可以选择关系型数据库、列式数据库或者NoSQL数据库等。根据不同的业务需求和数据特点,选择合适的存储方式和分区策略可以提高查询效率和降低存储成本。同时,还可以通过数据压缩、索引优化等方式来进一步提升性能。
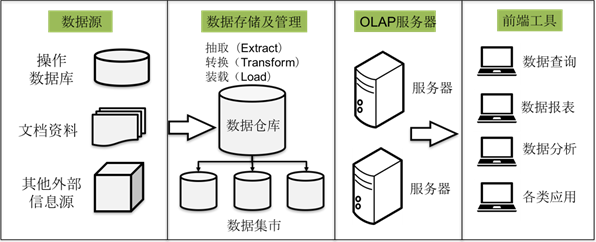
数据集成是将不同数据源的数据整合到一起的过程,而ETL流程是将源数据清洗、转换和加载到数据仓库的过程。在设计过程中,可以通过并行化、增量抽取和自动化等技术手段来提高数据集成和ETL流程的效率,减少数据延迟和错误。
对于敏感数据和重要数据,需要设置合理的权限和访问控制。同时,还需要定期进行数据备份和恢复,以保证数据的完整性和可用性。数据安全和权限管理是数据仓库模型设计中不可忽视的一环。
综上所述,设计一个高效的数据仓库模型是一个复杂而关键的任务。需要充分了解业务需求和数据特点,选择合适的建模方法和技术,考虑数据的存储和分区策略,优化数据集成和ETL流程,并确保数据的安全和权限管理。通过这些步骤,可以构建一个可靠、可扩展的数据管理体系,提高数据处理和分析的效率。
FineDataLink是一款低代码/高效率的ETL工具,同时也是一款数据集成工具,它可以帮助企业快速构建数据仓库,对数据进行管理、分析和使用,提高数据治理效率和质量。同时,帆软FDL也支持开放API和服务接口,可以与其他数据工具和系统进行整合和拓展。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 五大数据仓库解决方案和平台下一篇: 终于能把数据仓库和人工智能的结合看懂了!


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号



