作者:finedatalink
发布时间:2023.8.18
阅读次数:1,032 次浏览
在现代的业务环境下,数据同步和计算是企业中至关重要的任务。每个企业都有其独特的业务场景和需求,因此需要定制化的策略来处理数据。插件引擎是一种强大的工具,可以帮助企业根据不同的业务场景,定制化数据处理的流程。下面我们将详细介绍如何使用插件引擎来定制数据同步和计算策略。
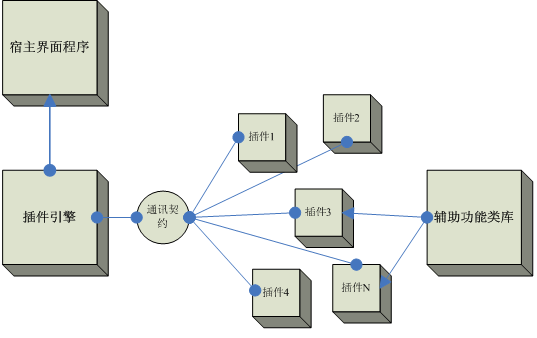
插件引擎是一种用于扩展系统功能的工具,它允许用户编写自定义的插件,以修改和定制系统的行为。在数据同步和计算中,插件引擎可以用于实现数据的过滤、转换、聚合等操作。通常,插件引擎由一个核心引擎和多个插件组成。核心引擎负责管理插件的载入和执行,而插件则实现具体的功能。
插件引擎的基本原理是通过定义一系列的事件和钩子来触发插件的执行。当某个事件发生时,核心引擎会依次执行注册的插件,以完成相应的操作。这样,用户可以通过编写自己的插件,来定制数据处理的流程。
使用插件引擎定制数据同步和计算策略可以帮助企业更好地适应不同的业务场景。下面是几个常见的应用场景和相应的解决方案:
1. 数据过滤:在数据同步过程中,有时需要根据特定的条件来过滤数据。例如,某个业务场景只需要同步某个特定日期范围内的数据。这时,可以编写一个插件,在数据同步之前进行日期的比较,只同步满足条件的数据。
2. 数据转换:在数据同步和计算过程中,有时需要对数据进行转换。例如,一个业务场景需要将不同系统的数据进行合并和统一格式化。这时,可以编写一个插件,对数据进行转换和格式化操作,以满足业务需求。
3. 数据聚合:在某些业务场景中,需要对多个数据源进行聚合计算。例如,一个电商平台需要对不同销售渠道的订单数据进行统计和分析。这时,可以编写一个插件,将不同数据源的数据进行聚合计算,生成相应的报表和统计结果。
4. 数据校验:数据质量是企业中非常重要的问题。使用插件引擎可以方便地定制化数据校验策略,以确保数据的准确性和完整性。例如,可以编写一个插件,在数据同步之后对数据进行校验,检查是否存在异常或错误数据。
使用插件引擎定制数据同步和计算策略可以帮助企业更好地适应不同的业务场景。通过编写自定义的插件,可以实现数据的过滤、转换、聚合和校验等操作,以满足不同的业务需求。
在使用插件引擎时,需要根据具体的业务场景和需求,编写相应的插件,并进行测试和优化。同时,需要注意插件的性能和稳定性,以保证系统的正常运行。
通过定制化的数据处理策略,企业可以提高数据处理的效率和质量,满足不同业务需求。插件引擎的灵活性和可扩展性使得它成为处理大规模数据的重要工具。
FineDataLink是一款低代码/高效率的ETL工具,同时也是一款数据集成工具,它可以帮助企业快速构建数据仓库,对数据进行管理、分析和使用,提高数据治理效率和质量。FDL在进行iPaaS领域的尝试,结合流批一体引擎、流程调度引擎,打造具有帆软特点的集成平台,通过全新的插件引擎,能够极大程度让用户自定义各类数据源的同步、计算、流程控制和调度策略。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号



